
У топі пошукових запитів! Велика модель Meituan стала популярною завдяки "швидкості"

Розробники з Китаю та інших країн: перевірили на практиці, нова відкрита модель Meituan надзвичайно швидка!
Коли AI дійсно стане таким же повсюдним, як вода чи електрика, питання про потужність моделі вже не буде єдиним, що турбує користувачів.
Від Claude 3.7 Sonnet, Gemini 2.5 Flash на початку року до нещодавніх GPT-5 і DeepSeek V3.1 — провідні розробники моделей постійно шукають відповідь на питання: як забезпечити, щоб AI вирішував кожну задачу з мінімальними обчислювальними витратами і давав відповідь у найкоротший термін, не втрачаючи точності? Іншими словами, як не марнувати ні токени, ні час.
Для компаній і розробників, які створюють застосунки на основі моделей, така зміна фокусу — від «побудови найпотужнішої моделі» до «створення більш практичної та швидкої моделі» — це гарна новина. Ще приємніше, що кількість open-source моделей, пов’язаних із цим підходом, поступово зростає.
Декілька днів тому ми знову знайшли нову модель на HuggingFace — LongCat-Flash-Chat.

Ця модель належить до серії LongCat-Flash від Meituan, доступна для використання на офіційному сайті.
Вона спочатку враховує, що «не всі токени однакові», тому динамічно розподіляє обчислювальний бюджет для важливих токенів. Завдяки цьому, активуючи лише невелику кількість параметрів, вона досягає продуктивності, порівнянної з провідними open-source моделями.

LongCat-Flash після відкриття коду потрапила в тренди.
Крім того, швидкість цієї моделі справила сильне враження — на відеокарті H800 швидкість інференсу перевищує 100 токенів за секунду. Це підтвердили як китайські, так і закордонні розробники — хтось досяг 95 токенів/с, а хтось отримав відповідь, порівнянну з Claude, за мінімальний час.
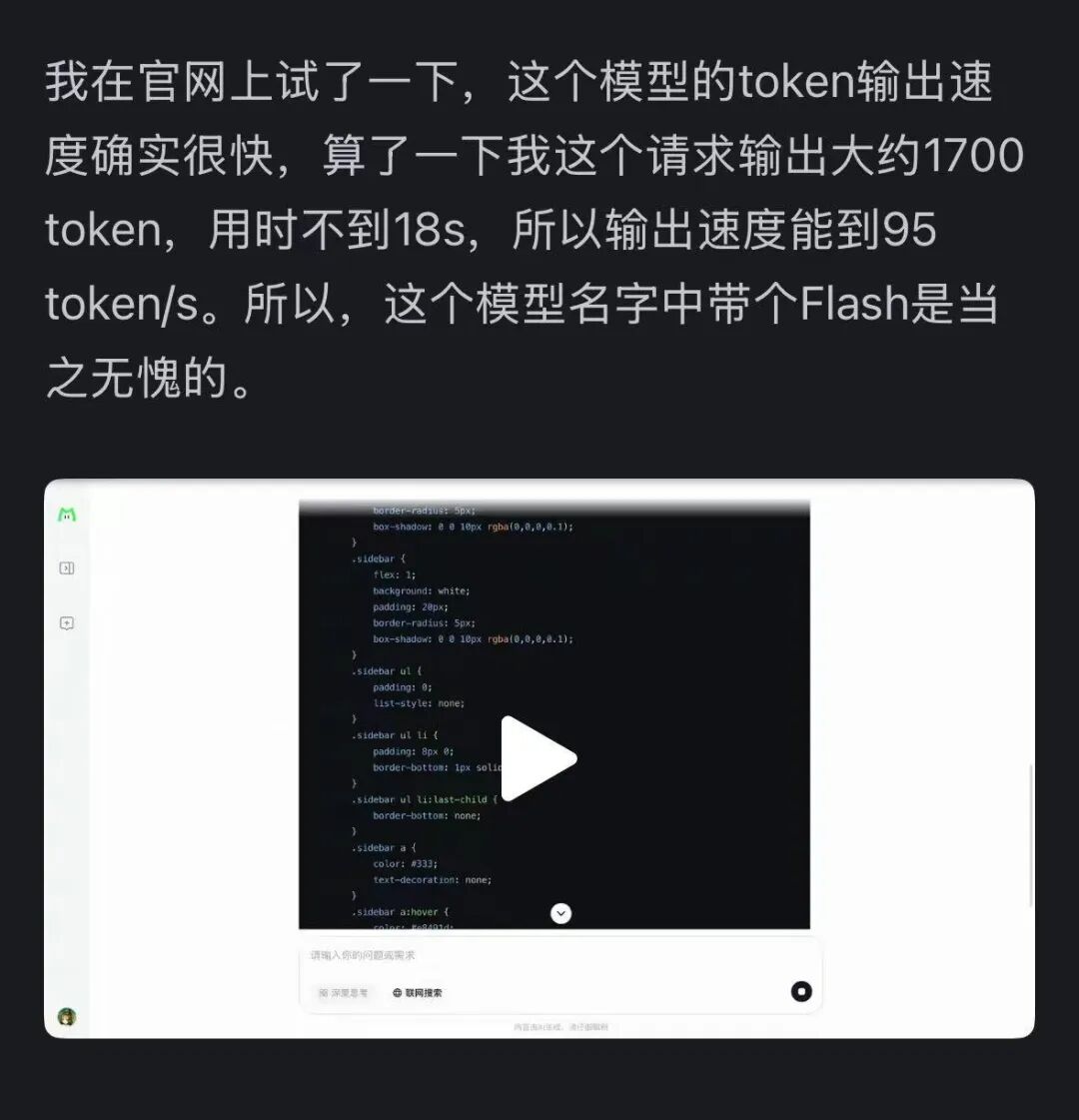
Джерело зображення: користувач Zhihu @小小将.
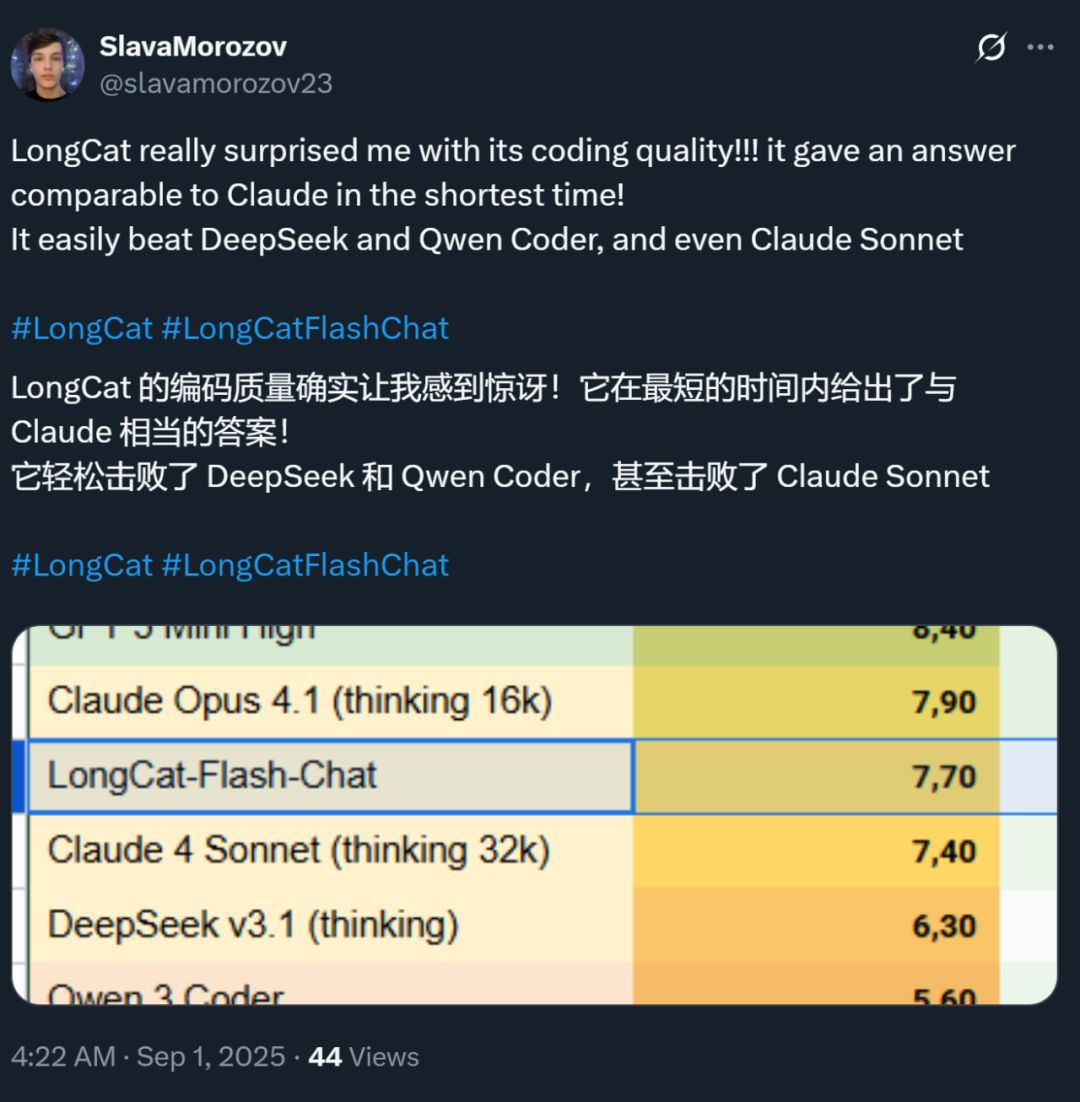
Джерело зображення: користувач X @SlavaMorozov.
Разом із відкриттям коду Meituan також опублікував технічний звіт LongCat-Flash, де можна знайти чимало технічних деталей.

Технічний звіт: LongCat-Flash Technical Report
У цій статті ми детально розповімо про це.
Як великі моделі економлять обчислювальні ресурси?
Погляньмо на архітектурні інновації та методи навчання LongCat-Flash
LongCat-Flash — це гібридна експертна модель із загальною кількістю параметрів 560 мільярдів, яка може активувати від 18.6 до 31.3 мільярдів (у середньому 27 мільярдів) параметрів залежно від контексту.
Для навчання цієї моделі було використано понад 200 трильйонів токенів, але час навчання склав менше 30 днів. При цьому система досягла 98.48% часу доступності, майже не потребуючи втручання людини для усунення збоїв — тобто весь процес навчання був практично «без участі людини».
Ще більш вражаюче, що модель, навчена таким чином, показує відмінні результати й під час розгортання.
Як показано на малюнку нижче, як не-рефлексивна модель, LongCat-Flash досягає продуктивності, порівнянної з SOTA не-рефлексивними моделями, такими як DeepSeek-V3.1 і Kimi-K2, при цьому має менше параметрів і швидший інференс. Це робить її конкурентоспроможною та практичною для загальних, програмних і агентських завдань.
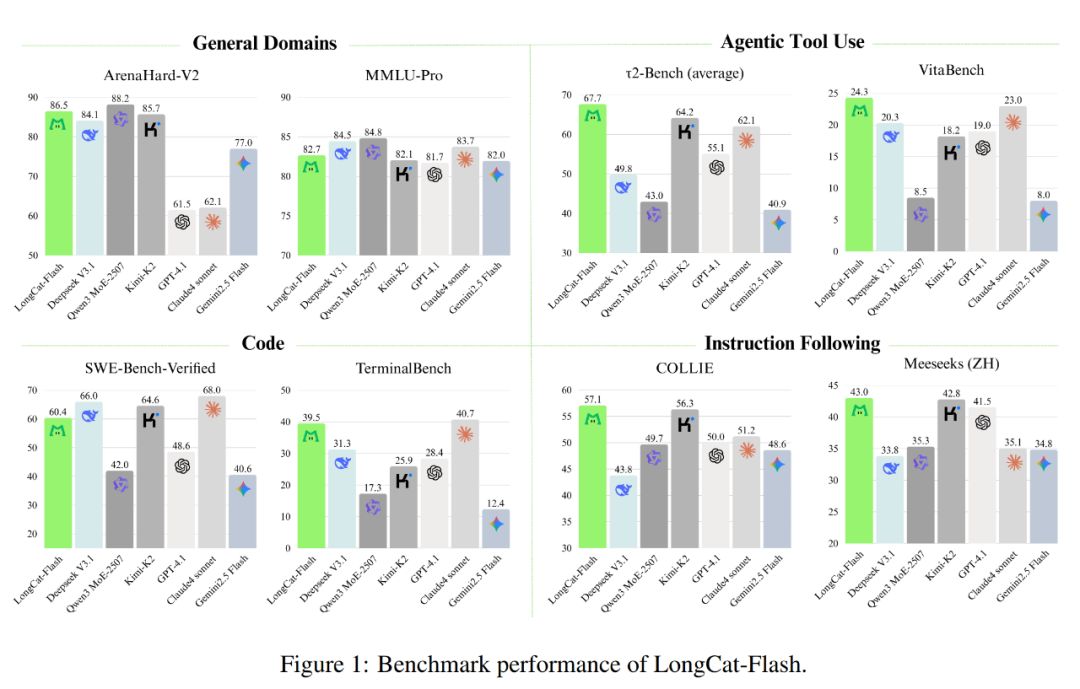
Крім того, її вартість також вражає — лише 0.7 долара за мільйон вихідних токенів. Це дуже вигідна ціна порівняно з іншими моделями такого ж масштабу на ринку.
З технічної точки зору, LongCat-Flash орієнтується на два основних завдання мовних моделей: обчислювальна ефективність і агентські можливості, поєднуючи архітектурні інновації та багатоступеневі методи навчання для створення масштабованої та інтелектуальної системи моделей.
В архітектурі моделі LongCat-Flash використовується новітня MoE-архітектура (рис. 2), яка має дві основні особливості:
Zero-computation Experts (експерти з нульовими обчисленнями);
Shortcut-connected MoE (ScMoE, MoE з короткими з'єднаннями).
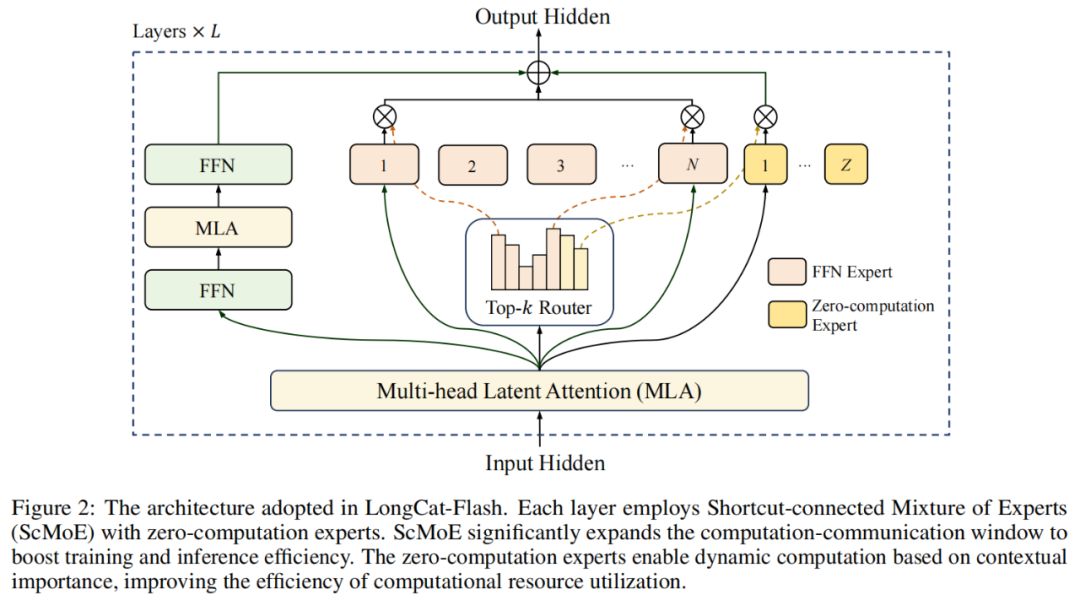
Zero-computation Experts
Основна ідея zero-computation experts полягає в тому, що не всі токени «рівні».
Це можна пояснити так: у реченні деякі слова дуже легко передбачити, наприклад, «的», «是», і майже не потребують обчислень, а інші, як-от імена людей, вимагають значно більше обчислень для точного прогнозу.
У попередніх дослідженнях зазвичай використовували такий підхід: незалежно від складності токена, для нього активується фіксована кількість (K) експертів, що призводить до значних обчислювальних втрат. Для простих токенів це зайве, а для складних — може бути недостатньо обчислювальних ресурсів.
Надихнувшись цим, LongCat-Flash запропонувала динамічний механізм розподілу обчислювальних ресурсів: за допомогою zero-computation experts для кожного токена динамічно активується різна кількість експертів FFN (Feed-Forward Network), щоб раціональніше розподіляти обчислення залежно від важливості в контексті.
Конкретно, у пулі експертів LongCat-Flash, окрім стандартних N експертів FFN, додано Z zero-computation experts. Zero-computation experts просто повертають вхідні дані як вихід, не створюючи додаткових обчислювальних витрат.
MoE-модуль у LongCat-Flash можна формалізувати так:
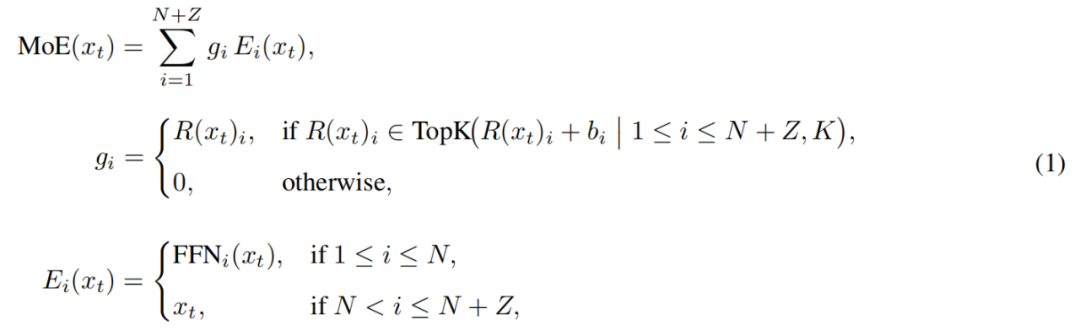
Тут x_t — t-й токен у вхідній послідовності, R — softmax-роутер, b_i — зсув для i-го експерта, K — кількість експертів, вибраних для кожного токена. Роутер розподіляє кожен токен між K експертами, причому кількість активованих FFN-експертів змінюється залежно від важливості токена в контексті. Завдяки такому адаптивному механізму розподілу модель може динамічно виділяти більше обчислювальних ресурсів для важливих токенів, досягаючи кращої продуктивності при однакових обчислювальних витратах, як показано на рис. 3a.
Крім того, при обробці вхідних даних модель має навчитися визначати, чи потрібно витрачати більше обчислювальних ресурсів на певний токен. Якщо не контролювати частоту вибору zero-computation experts, модель може віддавати перевагу експертам із обчисленнями, ігноруючи zero-computation experts, що знижує ефективність використання ресурсів.
Щоб вирішити цю проблему, Meituan удосконалив механізм зсуву експертів у стратегії aux-loss-free: було введено експертно-специфічний зсув, який динамічно коригує оцінку роутера залежно від останнього використання експерта, залишаючись при цьому незалежним від основної мети навчання мовної моделі.
Оновлення здійснюється за допомогою PID-контролера з теорії керування, який у реальному часі коригує зсув експертів. Завдяки цьому при обробці кожного токена модель активує лише 18.6–31.3 мільярдів (у середньому близько 27 мільярдів) параметрів, оптимізуючи використання ресурсів.
Shortcut-connected MoE
Ще одна особливість LongCat-Flash — механізм Shortcut-connected MoE.
Зазвичай ефективність великих MoE-моделей значною мірою обмежується витратами на комунікацію. У традиційній парадигмі експертний паралелізм створює послідовний робочий процес: спочатку потрібно виконати глобальну комунікацію для маршрутизації токенів до відповідних експертів, і лише потім починаються обчислення.
Такий порядок — спочатку комунікація, потім обчислення — призводить до додаткового часу очікування, особливо у великих розподілених тренуваннях, де затримки комунікації стають вузьким місцем.
Раніше дослідники намагалися вирішити цю проблему за допомогою архітектури спільних експертів, поєднуючи комунікацію з обчисленнями одного експерта, але ефективність обмежувалася малим вікном обчислень одного експерта.
Meituan подолав це обмеження, впровадивши архітектуру ScMoE, яка додає міжшарове shortcut-з'єднання. Це дозволяє обчислення щільного FFN попереднього шару виконувати паралельно з комунікацією dispatch/aggregate поточного MoE-шару, створюючи значно більше вікно перекриття комунікації та обчислень порівняно з архітектурою спільних експертів.
Ця архітектура була перевірена в багатьох експериментах.
По-перше, дизайн ScMoE не знижує якість моделі. Як показано на рис. 4, крива втрат для ScMoE майже ідентична базовій архітектурі без ScMoE, що доводить: така зміна порядку виконання не шкодить продуктивності моделі. Це підтверджено для різних конфігурацій.
Ще важливіше, що стабільність і переваги ScMoE не залежать від конкретного вибору механізму уваги (attention mechanism) — тобто стабільність і вигода зберігаються незалежно від типу attention.
По-друге, ScMoE забезпечує значне підвищення ефективності на системному рівні як під час тренування, так і під час інференсу. Зокрема:
У великомасштабному тренуванні: розширене вікно перекриття дозволяє обчисленням попередніх блоків повністю перекриватися з комунікацією dispatch/aggregate у MoE-шарі, що досягається шляхом розбиття операцій на дрібні блоки по токенах.
Для ефективного інференсу: ScMoE підтримує перекриття pipeline в одному батчі, знижуючи теоретичний час виводу токена (TPOT) майже на 50% порівняно з провідними моделями, такими як DeepSeek-V3. Більше того, він дозволяє одночасно виконувати різні комунікаційні режими: внутрішньовузлову тензорну паралельну комунікацію (через NVLink) для щільного FFN і міжвузлову експертну паралельну комунікацію (через RDMA) для експертів, максимізуючи загальне використання мережі.
Отже, ScMoE забезпечує значне підвищення продуктивності без шкоди для якості моделі.
Стратегія масштабування моделі та багатоступеневе навчання
Meituan також запропонував ефективну стратегію масштабування моделі, яка значно покращує продуктивність при збільшенні розміру моделі.
По-перше, це перенесення гіперпараметрів: тестування різних конфігурацій на великих моделях дуже дорого і нестабільно, тому Meituan спочатку експериментує на менших моделях, знаходить найкращі гіперпараметри, а потім переносить їх на великі моделі, економлячи ресурси та забезпечуючи якість. Правила перенесення наведені в таблиці 1.
Далі — ініціалізація зростання моделі (Model Growth): Meituan починає з напівмасштабної моделі, попередньо натренованої на сотнях мільярдів токенів, зберігає чекпойнт, потім розширює модель до повного масштабу і продовжує тренування.
Завдяки цьому модель демонструє типову криву втрат: спочатку короткочасне зростання втрат, потім швидка збіжність і, зрештою, значно кращі результати, ніж при випадковій ініціалізації. На рис. 5b показано типовий результат для експерименту з 6B активованих параметрів, що ілюструє переваги ініціалізації зростання моделі.
Третій аспект — багаторівневий стабілізаційний пакет: Meituan підвищив стабільність тренування LongCat-Flash на рівні роутера, активації та оптимізатора.
Четвертий — детерміновані обчислення, що забезпечують повну відтворюваність результатів і виявлення «тихих» пошкоджень даних (Silent Data Corruption, SDC) під час тренування.
Завдяки цим заходам тренування LongCat-Flash залишається стабільним і не має непоправних стрибків втрат.
На основі стабільного тренування Meituan також ретельно розробив pipeline навчання, щоб LongCat-Flash мав розвинуту агентську поведінку. Процес включає великомасштабне попереднє навчання, середньострокове навчання для покращення навичок міркування та кодування, а також посттренування, орієнтоване на діалоги та використання інструментів.
На початковому етапі створюється базова модель, краще пристосована для подальшого агентського навчання; для цього Meituan розробив двоетапну стратегію злиття даних для попереднього навчання, щоб зосередитися на даних із доменів, насичених міркуваннями.
На середньому етапі Meituan додатково підсилює навички міркування та кодування моделі; також розширює довжину контексту до 128k для задоволення потреб агентського навчання.
Нарешті, Meituan проводить багатоступеневе посттренування. Через дефіцит якісних і складних навчальних даних для агентських задач Meituan розробив багатозадачний синтетичний фреймворк: він визначає складність завдань за трьома вимірами — обробка інформації, складність набору інструментів і взаємодія з користувачем, використовуючи спеціальний контролер для генерації складних завдань, що вимагають ітеративного міркування та взаємодії з середовищем.
Завдяки такому дизайну модель чудово справляється із завданнями, що вимагають використання інструментів і взаємодії з середовищем.
Швидко і дешево в роботі
Як LongCat-Flash цього досяг?
Як згадувалося раніше, LongCat-Flash може виконувати інференс на H800 із швидкістю понад 100 токенів/с, а вартість складає лише 0.7 долара за мільйон вихідних токенів — тобто працює швидко й дешево.
Як це вдалося? По-перше, вони мають паралельну архітектуру інференсу, спроектовану разом із архітектурою моделі; по-друге, вони додали оптимізації, такі як квантизація та кастомні ядра.
Спеціалізовані оптимізації: щоб модель «сама бігала швидко»
Відомо, що для побудови ефективної системи інференсу потрібно вирішити дві ключові проблеми: координацію обчислень і комунікацій, а також читання/запис і зберігання KV-кешу.
Щодо першої проблеми, існуючі методи зазвичай використовують паралелізм на трьох рівнях: перекриття на рівні операторів, експертів і шарів. ScMoE-архітектура LongCat-Flash додає четвертий рівень — перекриття на рівні модулів. Для цього команда розробила SBO (Single Batch Overlap) стратегію планування для оптимізації затримки та пропускної здатності.
SBO — це чотириетапний pipeline-виконання, що повністю використовує потенціал LongCat-Flash завдяки перекриттю на рівні модулів, як показано на рис. 9. Відмінність SBO від TBO полягає в тому, що комунікаційні витрати приховуються всередині одного батчу. На першому етапі виконується MLA-обчислення, що забезпечує вхід для наступних етапів; на другому — перекриваються обчислення Dense FFN і Attn 0 (QKV-проекція) з all-to-all dispatch-комунікацією; на третьому — незалежно виконується MoE GEMM, затримка якого виграє від широкої стратегії EP; на четвертому — Attn 1 (основна увага та вихідна проекція) і Dense FFN перекриваються з all-to-all combine. Такий дизайн ефективно знижує комунікаційні витрати, забезпечуючи високоефективний інференс LongCat-Flash.
Щодо другої проблеми — читання/запису та зберігання KV-кешу — LongCat-Flash вирішує її завдяки архітектурним інноваціям у механізмі уваги та структурі MTP, зменшуючи ефективні I/O-витрати.
По-перше, прискорення спекулятивного декодування. LongCat-Flash використовує MTP як драфтову модель, оптимізуючи три ключові фактори через системний аналіз формули прискорення спекулятивного декодування: очікувану довжину прийняття, співвідношення вартості драфтової та цільової моделей, а також співвідношення вартості перевірки цілі та декодування. Інтегруючи одну MTP-голову та вводячи її на пізньому етапі попереднього навчання, досягається близько 90% прийняття. Для балансу якості драфту та швидкості використовується легка MTP-архітектура з меншою кількістю параметрів, а також метод C2T для фільтрації малоймовірних токенів через класифікаційну модель.
По-друге, оптимізація KV-кешу через 64-головий механізм уваги MLA. MLA забезпечує баланс між продуктивністю та ефективністю, значно знижуючи обчислювальне навантаження та забезпечуючи ефективне стиснення KV-кешу, зменшуючи навантаження на зберігання та пропускну здатність. Це критично для pipeline LongCat-Flash, оскільки модель завжди має обчислення уваги, які не можна перекрити з комунікацією.
Системні оптимізації: щоб апаратне забезпечення «працювало командно»
Щоб мінімізувати витрати на планування, команда LongCat-Flash вирішила проблему launch-bound, спричинену витратами на запуск ядер у LLM-системах інференсу. Особливо після впровадження спекулятивного декодування незалежне планування ядер для верифікації та драфтового forward-проходу створює значні витрати. Завдяки стратегії TVD-ф'южн вони об'єднали цільовий forward, верифікацію та драфтовий forward в одну CUDA-графіку. Для подальшого підвищення використання GPU вони реалізували overlapped scheduler і ввели multi-step overlapped scheduler, який запускає кілька forward-кроків у межах однієї ітерації планування, ефективно приховуючи витрати на планування та синхронізацію CPU.
Кастомні ядра оптимізовані для унікальних викликів ефективності автогенеративного інференсу LLM. На етапі prefill обчислення інтенсивні, а на етапі декодування через патерни трафіку розміри батчів малі й нерегулярні, що часто обмежується пам’яттю. Для MoE GEMM використовується технологія SwapAB, де ваги розглядаються як ліва матриця, а активації — як права, максимізуючи використання тензорних ядер завдяки гнучкості 8-елементних блоків по n-виміру. Комунікаційні ядра використовують апаратне прискорення NVLink Sharp для broadcast і in-switch reduction, мінімізуючи переміщення даних і використання SM, і перевершують NCCL і MSCCL++ у діапазоні розмірів повідомлень від 4KB до 96MB, використовуючи лише 4 блоки потоків.
Щодо квантизації, LongCat-Flash використовує такий самий дрібноблочний підхід, як DeepSeek-V3. Для досягнення оптимального балансу між продуктивністю та точністю застосовується ієрархічна змішана квантизація: перший підхід виявляє, що деякі лінійні шари (особливо Downproj) мають вхідні активації з амплітудою до 10^6; другий — обчислює блочну FP8-помилку квантизації для кожного шару, виявляючи значну помилку в окремих експертних шарах. Перетин двох підходів дає значне підвищення точності.
Практичні дані: наскільки швидко і дешево?
Реальні тести показують, що LongCat-Flash демонструє відмінну продуктивність у різних налаштуваннях. Порівняно з DeepSeek-V3, при схожій довжині контексту LongCat-Flash забезпечує вищу пропускну здатність і швидше генерування.
У застосуваннях Agent, враховуючи різницю між інференсом контенту (видимий користувачу, має відповідати швидкості читання людини — близько 20 токенів/с) і командними діями (невидимі користувачу, але впливають на час запуску інструментів, вимагають максимальної швидкості), швидкість генерації LongCat-Flash близько 100 токенів/с дозволяє тримати затримку виклику інструменту менше 1 секунди, значно покращуючи інтерактивність Agent-застосунків. При вартості H800 GPU 2 долари на годину це означає ціну 0.7 долара за мільйон вихідних токенів.
Теоретичний аналіз продуктивності показує, що затримка LongCat-Flash визначається трьома компонентами: MLA, all-to-all dispatch/combine і MoE. При EP=128, batch=96 на карту, прийнятті MTP ≈80% теоретичний TPOT LongCat-Flash становить 16 мс, що значно краще за DeepSeek-V3 (30 мс) і Qwen3-235B-A22B (26.2 мс). При вартості H800 GPU 2 долари на годину LongCat-Flash має вартість виводу 0.09 долара за мільйон токенів, що значно дешевше за DeepSeek-V3 (0.17 долара). Проте це лише теоретичні межі.
Ми також протестували LongCat-Flash на безкоштовній демо-сторінці.
Спочатку ми попросили цю велику модель написати статтю про осінь на 1000 слів.
Щойно ми сформулювали запит і відкрили запис екрану, LongCat-Flash уже видала відповідь — ми навіть не встигли вчасно зупинити запис.
Якщо придивитися, перший токен LongCat-Flash з’являється надзвичайно швидко. З іншими діалоговими моделями часто доводиться чекати, що випробовує терпіння користувача — як коли ви поспішаєте прочитати повідомлення у WeChat, а телефон показує «отримання». LongCat-Flash змінює цей досвід — затримка першого токена майже не відчувається.
Далі токени також генеруються дуже швидко, значно випереджаючи швидкість читання людиною.
Далі ми увімкнули «пошук у мережі», щоб перевірити, наскільки швидко LongCat-Flash справляється з цією задачею. Ми попросили LongCat-Flash порекомендувати хороші ресторани поблизу Wangjing.
Під час тесту було очевидно, що LongCat-Flash не «думає» довго перед відповіддю, а майже миттєво видає результат. Пошук у мережі також відчувається «швидким». Більше того, модель не лише швидко відповідає, а й надає посилання на джерела, що забезпечує достовірність і відстежуваність інформації.
Якщо у вас є можливість завантажити модель, спробуйте запустити LongCat-Flash локально і переконайтеся, чи її швидкість така ж вражаюча.
Коли великі моделі стають практичними
Останніми роками, коли з’являлася нова велика модель, усіх цікавило: які її benchmark-результати? Скільки рейтингів вона оновила? Чи є вона SOTA? Тепер ситуація змінилася. При схожих можливостях користувачі більше цікавляться: чи дорога ця модель у використанні? Яка її швидкість? Це особливо актуально для компаній і розробників, які використовують open-source моделі. Адже багато хто обирає open-source, щоб зменшити залежність і витрати на закриті API, тому вони чутливі до вимог до обчислювальних ресурсів, швидкості інференсу та ефективності квантизації.
Відкрита LongCat-Flash від Meituan — яскравий приклад цієї тенденції. Вони зосередилися на тому, як зробити великі моделі дійсно доступними та швидкими — це ключ до поширення технології.
Такий практичний підхід відповідає нашому враженню про Meituan. У минулому більшість їхніх технічних інвестицій були спрямовані на вирішення реальних бізнес-проблем: наприклад, EDPLVO, що отримала нагороду ICRA за найкращу навігаційну статтю у 2022 році, була створена для вирішення проблем із безпілотниками під час доставки (наприклад, втрата сигналу через щільну забудову); нещодавно Meituan брала участь у розробці глобального стандарту ISO для уникнення перешкод безпілотниками, що базується на досвіді уникнення повітряних зміїв і тросів для миття вікон. А LongCat-Flash — це модель, що лежить в основі їхнього AI-інструменту для програмування «NoCode», який використовується як всередині компанії, так і відкритий для зовнішніх користувачів, щоб кожен міг використовувати vibe coding для підвищення ефективності та зниження витрат.
Перехід від гонки за продуктивністю до практичної орієнтації відображає природний розвиток AI-індустрії. Коли можливості моделей вирівнюються, інженерна ефективність і вартість розгортання стають ключовими факторами диференціації. Відкриття LongCat-Flash — лише один із прикладів цієї тенденції, але він дійсно пропонує спільноті технічний шлях: як зберегти якість моделі, знижуючи поріг використання завдяки архітектурним і системним інноваціям. Це безцінно для розробників і компаній із обмеженим бюджетом, які прагнуть використовувати сучасні AI-можливості.
Відмова від відповідальності: зміст цієї статті відображає виключно думку автора і не представляє платформу в будь-якій якості. Ця стаття не повинна бути орієнтиром під час прийняття інвестиційних рішень.
Вас також може зацікавити
Залишилося менше місяця! Відлік часу до "закриття" уряду США знову почався
Це не лише питання грошей! Справа Епштейна, федеральні агенти та інші "міни" можуть спровокувати кризу із закриттям уряду США...
QuBitDEX став генеральним спонсором першого Тайванського онлайн-саміту з блокчейну (TBOS), створюючи найбільший онлайн-індустріальний захід в Азії
Перший Тайванський онлайн-саміт з блокчейну TBOS відбудеться у вересні 2025 року у співпраці з TBW, MYBW та іншими партнерами, зосереджуючись на децентралізованих додатках і переході від Web2 до Web3, щоб створити найбільший в Азії онлайн-захід Web3.

