
¡En tendencia! El modelo de IA de Meituan se vuelve popular gracias a su “rapidez”

Desarrolladores nacionales e internacionales: ¡comprobado, el modelo recientemente open source de Meituan es rapidísimo!
Cuando la IA realmente se vuelve tan común como el agua y la electricidad, la potencia del modelo deja de ser la única preocupación de todos.
Desde el Claude 3.7 Sonnet y Gemini 2.5 Flash de principios de año hasta los recientes GPT-5 y DeepSeek V3.1, todos los fabricantes de modelos líderes están pensando: ¿cómo lograr que la IA, garantizando la precisión, resuelva cada problema con el menor poder de cómputo posible y responda en el menor tiempo? En otras palabras, ¿cómo evitar desperdiciar tokens y tiempo?
Para las empresas y desarrolladores que construyen aplicaciones sobre modelos, este cambio de “simplemente construir el modelo más potente” a “construir modelos más prácticos y rápidos” es una buena noticia. Y lo mejor es que cada vez hay más modelos open source relacionados con esto.
Hace unos días, encontramos un nuevo modelo en HuggingFace: LongCat-Flash-Chat.

Este modelo proviene de la serie LongCat-Flash de Meituan, y se puede usar directamente en su sitio oficial.
De forma nativa entiende que “no todos los tokens son iguales”, por lo que asigna dinámicamente presupuesto de cómputo a los tokens importantes según su relevancia. Así, activando solo una pequeña cantidad de parámetros, su rendimiento puede igualar a los modelos open source líderes actuales.

LongCat-Flash se volvió tendencia tras ser open source.
Al mismo tiempo, la velocidad de este modelo también ha dejado una impresión profunda: en una GPU H800, la velocidad de inferencia supera los 100 tokens por segundo. Las pruebas de desarrolladores nacionales e internacionales lo confirman: algunos lograron 95 tokens/s, otros obtuvieron respuestas comparables a Claude en muy poco tiempo.
Fuente: usuario de Zhihu @小小将.
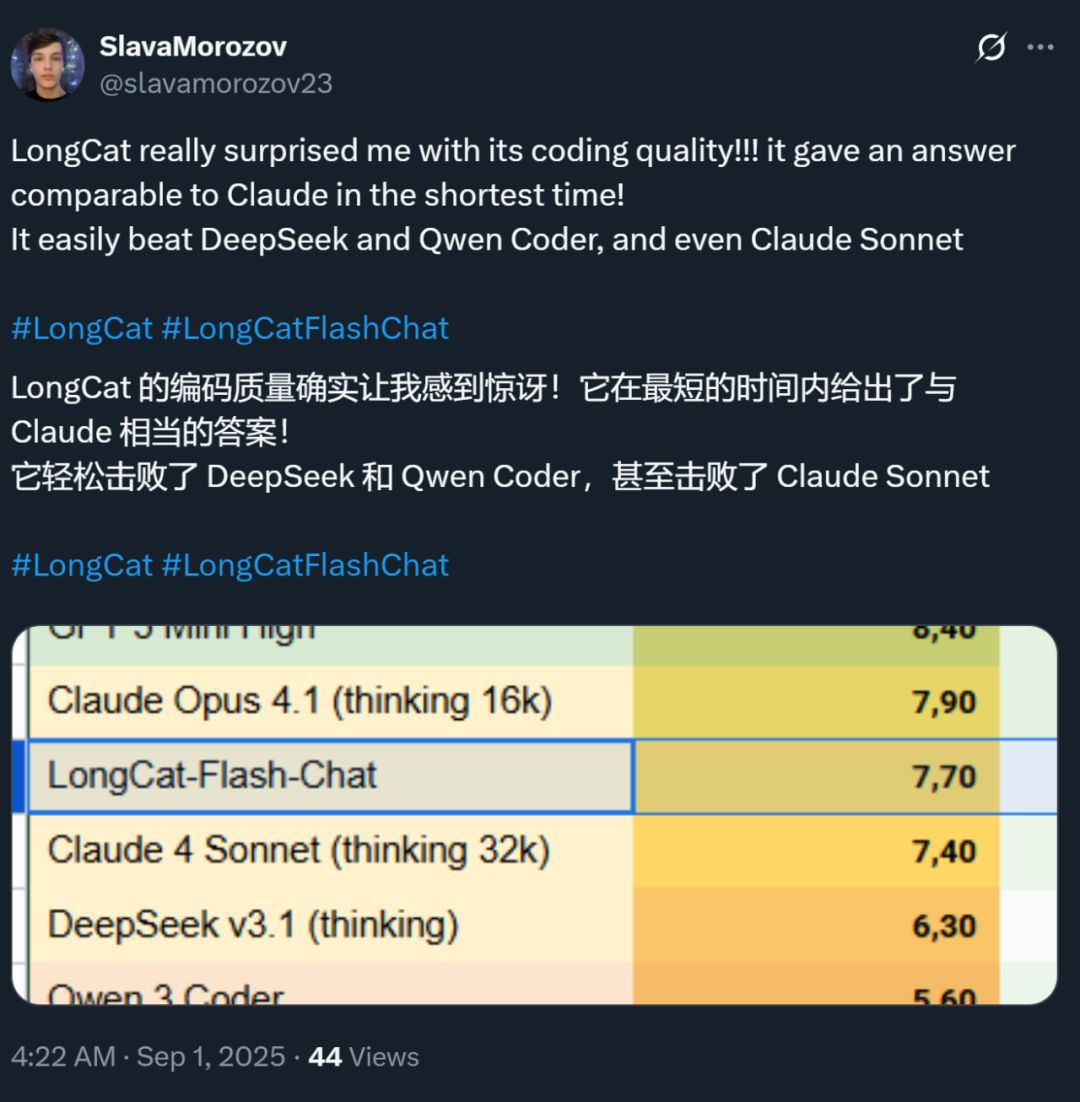
Fuente: usuario de X @SlavaMorozov.
Junto con el modelo open source, Meituan también publicó el informe técnico de LongCat-Flash, donde se pueden ver muchos detalles técnicos.

Informe técnico: LongCat-Flash Technical Report
En este artículo, lo presentaremos en detalle.
¿Cómo ahorra poder de cómputo un modelo grande?
Mirá la innovación arquitectónica y los métodos de entrenamiento de LongCat-Flash
LongCat-Flash es un modelo de expertos mixtos con un total de 560 mil millones de parámetros, capaz de activar entre 18.6 y 31.3 mil millones (promedio 27 mil millones) de parámetros según las necesidades del contexto.
La cantidad de datos utilizada para entrenar este modelo supera los 20 trillones de tokens, pero el tiempo de entrenamiento fue de menos de 30 días. Además, durante ese tiempo, el sistema alcanzó una disponibilidad del 98,48%, casi sin intervención humana para resolver fallos, lo que significa que el proceso de entrenamiento fue prácticamente “sin intervención” y automático.
Aún más impresionante es que el modelo entrenado de esta manera también se desempeña excelentemente en el despliegue real.
Como se muestra a continuación, como modelo no reflexivo, LongCat-Flash logró un rendimiento comparable a los modelos SOTA no reflexivos, incluyendo DeepSeek-V3.1 y Kimi-K2, con menos parámetros y mayor velocidad de inferencia. Esto lo hace muy competitivo y práctico en áreas como uso general, programación y herramientas de agentes inteligentes.
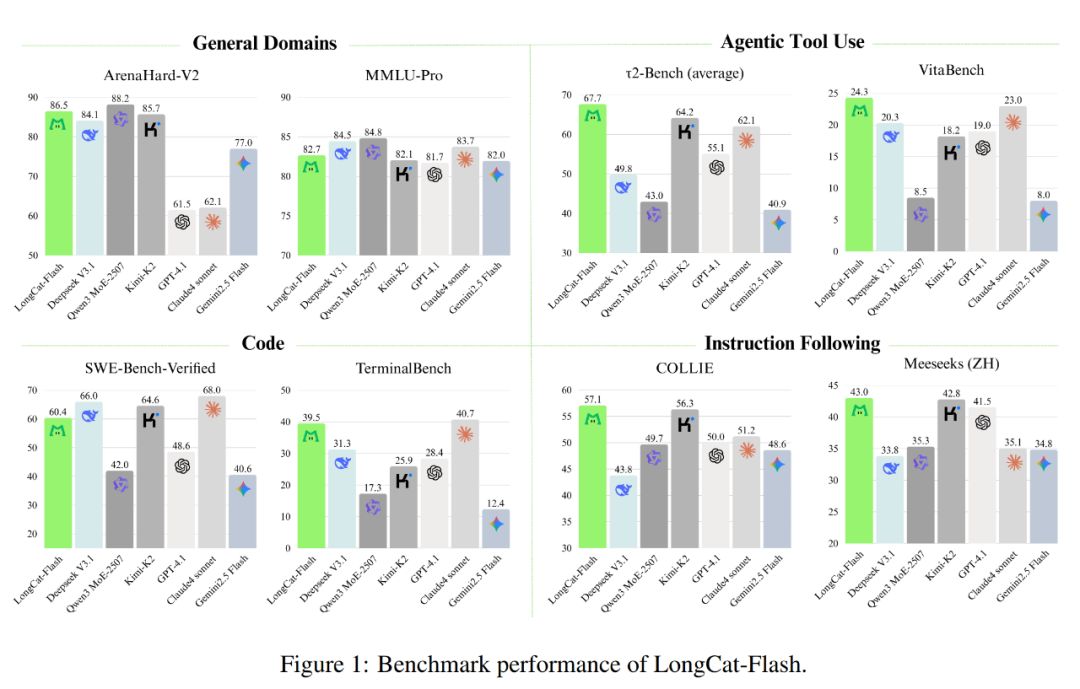
Además, su costo es muy atractivo, de solo 0,7 dólares por cada millón de tokens generados. Este precio es muy competitivo en comparación con modelos de escala similar en el mercado.
Desde el punto de vista técnico, LongCat-Flash apunta principalmente a dos objetivos de los modelos de lenguaje: eficiencia computacional y capacidad de agente, fusionando innovación arquitectónica y métodos de entrenamiento en varias etapas para lograr un sistema de modelos escalable e inteligente.
En cuanto a la arquitectura, LongCat-Flash adopta una novedosa arquitectura MoE (ver figura 2), con dos puntos destacados:
Expertos de cero cómputo (Zero-computation Experts);
MoE con conexiones rápidas (Shortcut-connected MoE, ScMoE).
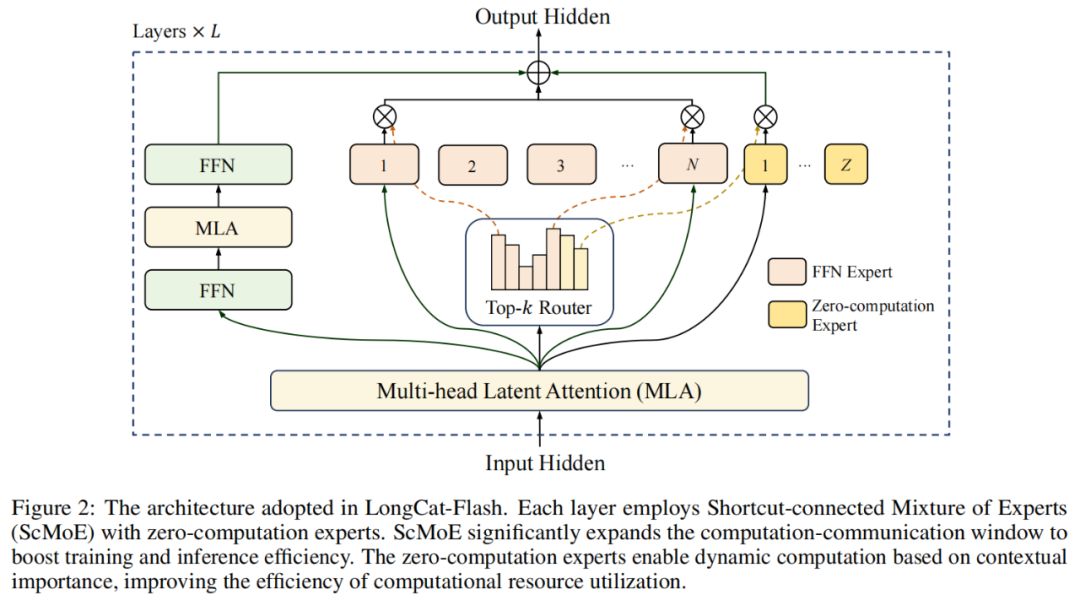
Expertos de cero cómputo
La idea central de los expertos de cero cómputo es que no todos los tokens son “iguales”.
Podemos entenderlo así: en una oración, algunas palabras son muy fáciles de predecir, como “de” o “es”, que casi no requieren cálculo, mientras que otras como nombres propios requieren mucho cálculo para predecirse con precisión.
En investigaciones previas, se solía usar el siguiente método: sin importar si el token es simple o complejo, siempre se activaba una cantidad fija (K) de expertos, lo que generaba un gran desperdicio de cómputo. Para los tokens simples, no hacía falta llamar a tantos expertos, y para los complejos, quizás faltaba suficiente asignación de cómputo.
Inspirado en esto, LongCat-Flash propone un mecanismo de asignación dinámica de recursos computacionales: mediante expertos de cero cómputo, activa dinámicamente diferentes cantidades de expertos FFN (Feed-Forward Network) para cada token, asignando así el cómputo de manera más razonable según la importancia contextual.
En concreto, LongCat-Flash amplía su pool de expertos añadiendo Z expertos de cero cómputo además de los N expertos FFN estándar. Los expertos de cero cómputo simplemente devuelven la entrada tal cual como salida, sin añadir carga computacional extra.
El módulo MoE de LongCat-Flash puede formalizarse así:
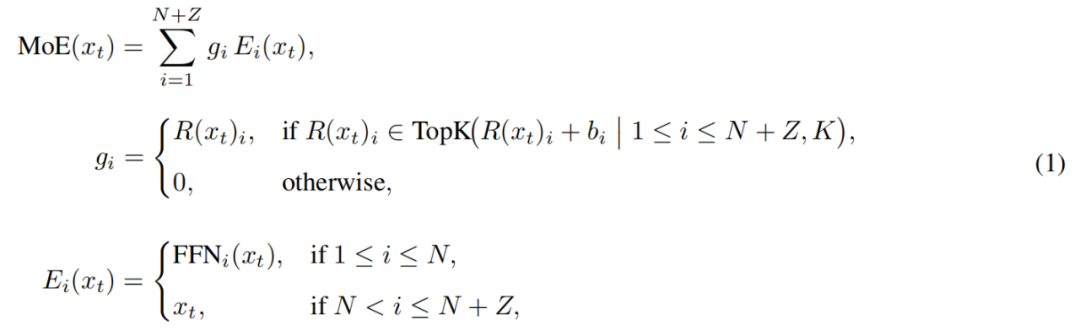
Donde x_t es el token t-ésimo de la secuencia de entrada, R es el router softmax, b_i es el sesgo del experto i, y K es la cantidad de expertos seleccionados por token. El router asigna cada token a K expertos, y la cantidad de expertos FFN activados varía según la importancia contextual del token. Con este mecanismo adaptativo, el modelo aprende a asignar más recursos computacionales a los tokens más importantes del contexto, logrando así mejor rendimiento con la misma cantidad de cómputo, como se muestra en la figura 3a.
Además, el modelo debe aprender a decidir, según la importancia de cada token, si vale la pena gastar más recursos computacionales. Si no se controla la frecuencia con la que se seleccionan los expertos de cero cómputo, el modelo podría preferir expertos con cómputo, ignorando el papel de los de cero cómputo, lo que reduciría la eficiencia de los recursos.
Para resolver esto, Meituan mejoró el mecanismo de sesgo de expertos en la estrategia aux-loss-free: introdujo un sesgo específico para cada experto, que puede ajustar dinámicamente la puntuación de enrutamiento según el uso reciente del experto, manteniéndose desacoplado del objetivo de entrenamiento del modelo de lenguaje.
La regla de actualización utiliza un controlador PID de teoría de control para ajustar en tiempo real el sesgo de los expertos. Gracias a esto, al procesar cada token, el modelo solo necesita activar entre 18.6 y 31.3 mil millones (promedio estable de 27 mil millones) de parámetros, optimizando la configuración de recursos.
MoE con conexiones rápidas
Otro punto destacado de LongCat-Flash es el mecanismo MoE con conexiones rápidas.
Por lo general, la eficiencia de los modelos MoE a gran escala está muy limitada por los costos de comunicación. En el paradigma tradicional, la paralelización de expertos introduce un flujo de trabajo secuencial: primero se debe realizar una operación de comunicación global para enrutar los tokens a sus expertos asignados, y solo después puede comenzar el cálculo.
Este orden de primero comunicar y luego calcular genera tiempos de espera adicionales, especialmente en entrenamiento distribuido a gran escala, donde la latencia de comunicación puede aumentar significativamente y convertirse en un cuello de botella.
Investigadores previos intentaron usar arquitecturas de expertos compartidos para solapar la comunicación con el cálculo de un solo experto, pero la eficiencia estaba limitada por el pequeño tamaño de la ventana de cálculo de cada experto.
Meituan superó esta limitación introduciendo la arquitectura ScMoE, que agrega una conexión rápida entre capas, permitiendo que el cálculo del FFN denso de la capa anterior se ejecute en paralelo con la comunicación de distribución/agregación de la capa MoE actual. Así, se crea una ventana de solapamiento comunicación-cálculo mucho mayor que en la arquitectura de expertos compartidos.
Este diseño ha sido validado en múltiples experimentos.
Primero, el diseño ScMoE no reduce la calidad del modelo. Como se muestra en la figura 4, la curva de pérdida de entrenamiento de la arquitectura ScMoE es casi idéntica a la de la línea base sin ScMoE, lo que prueba que este reordenamiento de la ejecución no daña el rendimiento. Esto se verifica en varias configuraciones.
Aún más importante, estos resultados muestran que la estabilidad y las ventajas de rendimiento de ScMoE son ortogonales a la elección específica del mecanismo de atención (es decir, sin importar el mecanismo de atención, se mantiene la estabilidad y el beneficio).
En segundo lugar, la arquitectura ScMoE aporta grandes mejoras de eficiencia a nivel de sistema tanto en entrenamiento como en inferencia. Específicamente:
En entrenamiento a gran escala: la ventana de solapamiento extendida permite que el cálculo de los bloques anteriores se ejecute completamente en paralelo con la comunicación de distribución y agregación de la capa MoE, dividiendo las operaciones en bloques de grano fino a lo largo de la dimensión de tokens.
En inferencia eficiente: ScMoE soporta pipeline de solapamiento por batch único, reduciendo el tiempo teórico por token (TPOT) casi un 50% en comparación con modelos líderes como DeepSeek-V3. Más importante aún, permite la ejecución concurrente de diferentes modos de comunicación: la comunicación de tensor paralela dentro del nodo en el FFN denso (por NVLink) puede solaparse completamente con la comunicación de expertos entre nodos (por RDMA), maximizando el uso de la red.
En resumen, ScMoE ofrece grandes mejoras de rendimiento sin sacrificar la calidad del modelo.
Estrategia de expansión de modelo y entrenamiento en varias etapas
Meituan también propuso una estrategia eficiente de expansión de modelo que mejora significativamente el rendimiento al aumentar la escala.
Primero, la transferencia de hiperparámetros: al entrenar modelos de ultra gran escala, probar directamente varias configuraciones de hiperparámetros es costoso e inestable. Por eso, Meituan primero experimenta en modelos más pequeños para encontrar la mejor combinación de hiperparámetros, y luego los transfiere al modelo grande, ahorrando costos y asegurando resultados. Las reglas de transferencia se muestran en la tabla 1:
Luego, la inicialización de crecimiento de modelo: Meituan parte de un modelo a media escala preentrenado con cientos de miles de millones de tokens, guarda el checkpoint y luego lo expande a la escala completa para continuar el entrenamiento.
Con este método, el modelo muestra una curva de pérdida típica: primero sube brevemente y luego converge rápidamente, superando significativamente la línea base de inicialización aleatoria. La figura 5b muestra un resultado representativo en el experimento de 6B parámetros activados, demostrando la ventaja de la inicialización de crecimiento de modelo.
En tercer lugar, un kit de estabilidad multinivel: Meituan mejoró la estabilidad del entrenamiento de LongCat-Flash desde la estabilidad del router, la activación y el optimizador.
Cuarto, el cálculo determinista: este método garantiza la reproducibilidad total de los resultados experimentales y permite detectar la corrupción silenciosa de datos (Silent Data Corruption, SDC) durante el entrenamiento.
Gracias a estas medidas, el proceso de entrenamiento de LongCat-Flash se mantiene altamente estable y no presenta picos de pérdida irrecuperables.
Sobre la base de la estabilidad del entrenamiento, Meituan también diseñó cuidadosamente el pipeline de entrenamiento para dotar a LongCat-Flash de comportamientos avanzados de agente inteligente, cubriendo preentrenamiento a gran escala, entrenamiento intermedio enfocado en razonamiento y código, y post-entrenamiento enfocado en diálogo y uso de herramientas.
En la etapa inicial, se construye un modelo base más adecuado para el post-entrenamiento de agentes inteligentes, para lo cual Meituan diseñó una estrategia de fusión de datos de preentrenamiento en dos etapas para concentrar datos de dominios intensivos en razonamiento.
En la etapa intermedia, Meituan refuerza aún más la capacidad de razonamiento y código del modelo, y extiende la longitud de contexto a 128k para satisfacer las necesidades del post-entrenamiento de agentes inteligentes.
Por último, Meituan realizó un post-entrenamiento en varias etapas. Dada la escasez de datos de entrenamiento de alta calidad y dificultad en el área de agentes inteligentes, Meituan diseñó un marco de síntesis multiagente: define la dificultad de las tareas en tres dimensiones (procesamiento de información, complejidad del conjunto de herramientas e interacción con el usuario), usando un controlador especializado para generar tareas complejas que requieren razonamiento iterativo e interacción con el entorno.
Este diseño le permite destacar en tareas complejas que requieren llamadas a herramientas e interacción con el entorno.
Corre rápido y es barato
¿Cómo lo logra LongCat-Flash?
Como mencionamos antes, LongCat-Flash puede inferir a más de 100 tokens por segundo en una GPU H800, con un costo de solo 0,7 dólares por cada millón de tokens generados; es decir, es rápido y barato.
¿Cómo lo logran? Primero, tienen una arquitectura de inferencia paralela diseñada en conjunto con la arquitectura del modelo; segundo, incorporan métodos de optimización como cuantización y kernels personalizados.
Optimización dedicada: hacer que el modelo “corra solo”
Sabemos que para construir un sistema de inferencia eficiente, hay que resolver dos problemas clave: la coordinación entre cálculo y comunicación, y la lectura/escritura y almacenamiento de la caché KV.
Para el primer desafío, los métodos existentes suelen aprovechar la paralelización en tres niveles: solapamiento a nivel de operador, de experto y de capa. La arquitectura ScMoE de LongCat-Flash introduce un cuarto nivel: solapamiento a nivel de módulo. Para ello, el equipo diseñó la estrategia de scheduling SBO (Single Batch Overlap) para optimizar latencia y throughput.
SBO es una ejecución pipeline de cuatro etapas que explota al máximo el potencial de LongCat-Flash mediante solapamiento a nivel de módulo, como se muestra en la figura 9. A diferencia de TBO, SBO oculta el costo de comunicación dentro de un solo batch. En la primera etapa ejecuta el cálculo MLA, proporcionando entrada para las siguientes etapas; la segunda etapa solapa el FFN denso y Attn 0 (proyección QKV) con la comunicación all-to-all dispatch; la tercera ejecuta MoE GEMM de forma independiente, beneficiándose de la estrategia de despliegue EP; la cuarta solapa Attn 1 (atención central y proyección de salida) y FFN denso con all-to-all combine. Este diseño alivia eficazmente el costo de comunicación y asegura la inferencia eficiente de LongCat-Flash.
Para el segundo desafío —lectura/escritura y almacenamiento de la caché KV— LongCat-Flash lo resuelve mediante innovación en el mecanismo de atención y la arquitectura MTP, reduciendo el I/O efectivo.
Primero, aceleración de decodificación especulativa. LongCat-Flash usa MTP como modelo borrador, optimizando tres factores clave mediante análisis de sistema y fórmulas de aceleración de decodificación especulativa: longitud de aceptación esperada, relación de costo entre modelo borrador y objetivo, y relación de costo entre verificación y decodificación del objetivo. Integrando una sola cabeza MTP e introduciéndola en la etapa final del preentrenamiento, logra una tasa de aceptación de alrededor del 90%. Para equilibrar calidad y velocidad del borrador, utiliza una arquitectura MTP ligera y el método C2T para filtrar tokens poco probables mediante un modelo de clasificación.
Luego, optimización de la caché KV, mediante el mecanismo de atención de 64 cabezas de MLA. MLA equilibra rendimiento y eficiencia, reduce la carga computacional y logra una compresión excelente de la caché KV, aliviando la presión de almacenamiento y ancho de banda. Esto es clave para coordinar el pipeline de LongCat-Flash, ya que el modelo siempre tiene cálculos de atención que no pueden solaparse con la comunicación.
Optimización a nivel de sistema: hacer que el hardware “trabaje en equipo”
Para minimizar el costo de scheduling, el equipo de LongCat-Flash resolvió el problema launch-bound causado por el overhead de lanzamiento de kernels en sistemas de inferencia LLM. Especialmente tras introducir la decodificación especulativa, el scheduling independiente de los kernels de verificación y forward del borrador genera un overhead notable. Mediante la estrategia de fusión TVD, fusionaron el forward objetivo, la verificación y el forward del borrador en un solo grafo CUDA. Para mejorar aún más el uso de GPU, implementaron un scheduler solapado y un scheduler de solapamiento multietapa que lanza múltiples pasos forward en una sola iteración de scheduling, ocultando eficazmente el overhead de scheduling y sincronización de CPU.
La optimización de kernels personalizados aborda los desafíos de eficiencia únicos de la inferencia autoregresiva LLM. La etapa de prellenado es intensiva en cálculo, mientras que la etapa de decodificación suele estar limitada por memoria debido a los tamaños de batch pequeños e irregulares. Para MoE GEMM, usaron la técnica SwapAB, tratando los pesos como matriz izquierda y las activaciones como matriz derecha, maximizando el uso del tensor core con granularidad de 8 elementos en la dimensión n. Los kernels de comunicación usan la aceleración hardware de NVLink Sharp para broadcast y reducción in-switch, minimizando el movimiento de datos y el uso de SM, superando consistentemente a NCCL y MSCCL++ en rangos de mensajes de 4KB a 96MB usando solo 4 bloques de hilos.
En cuanto a cuantización, LongCat-Flash utiliza el mismo esquema de cuantización por bloques de grano fino que DeepSeek-V3. Para lograr el mejor equilibrio entre rendimiento y precisión, implementa cuantización mixta por capas basada en dos esquemas: el primero identifica que ciertas capas lineales (especialmente Downproj) tienen activaciones de entrada de magnitud extrema (hasta 10^6); el segundo calcula el error de cuantización FP8 por bloque en cada capa, encontrando errores significativos en capas de expertos específicas. Tomando la intersección de ambos esquemas, logra una mejora significativa en precisión.
Datos prácticos: ¿qué tan rápido y barato puede correr?
Las pruebas muestran que LongCat-Flash se desempeña excelentemente en diferentes configuraciones. Comparado con DeepSeek-V3, con longitudes de contexto similares, LongCat-Flash logra mayor throughput y velocidad de generación.
En aplicaciones de agentes, considerando la diferencia entre contenido de inferencia (visible para el usuario, debe coincidir con la velocidad de lectura humana de unos 20 tokens/s) y comandos de acción (invisibles para el usuario pero afectan directamente el tiempo de inicio de llamadas a herramientas, requieren máxima velocidad), la velocidad de generación de casi 100 tokens/s de LongCat-Flash mantiene la latencia de una llamada de herramienta por ronda en menos de 1 segundo, mejorando significativamente la interactividad de las aplicaciones de agentes. Suponiendo un costo de 2 dólares por hora de GPU H800, esto equivale a 0,7 dólares por cada millón de tokens generados.
El análisis teórico muestra que la latencia de LongCat-Flash depende principalmente de tres componentes: MLA, all-to-all dispatch/combine y MoE. Bajo las suposiciones de EP=128, batch por tarjeta=96 y tasa de aceptación MTP≈80%, el TPOT teórico límite de LongCat-Flash es de 16ms, significativamente mejor que los 30ms de DeepSeek-V3 y los 26,2ms de Qwen3-235B-A22B. Bajo el supuesto de 2 dólares por hora de GPU H800, el costo de salida de LongCat-Flash es de 0,09 dólares por millón de tokens, mucho menor que los 0,17 dólares de DeepSeek-V3. Sin embargo, estos valores son solo límites teóricos.
También probamos en la página de experiencia gratuita de LongCat-Flash.
Primero le pedimos a este gran modelo que escribiera un artículo sobre el otoño, de unas 1000 palabras.
Apenas hicimos la solicitud y comenzamos a grabar pantalla, LongCat-Flash ya había escrito la respuesta; ni siquiera alcanzamos a detener la grabación a tiempo.
Si observás con atención, notarás que la velocidad de salida del primer token de LongCat-Flash es especialmente rápida. Con otros modelos de diálogo, a menudo hay que esperar el “círculo girando”, poniendo a prueba la paciencia del usuario, como cuando querés ver un mensaje en WeChat y el teléfono muestra “recibiendo”. LongCat-Flash cambia esa experiencia: prácticamente no se percibe latencia en el primer token.
La velocidad de generación de los tokens siguientes también es muy rápida, mucho mayor que la velocidad de lectura humana.
Luego activamos la “búsqueda en línea” para ver si LongCat-Flash es igual de rápido en esta función. Le pedimos que recomendara buenos restaurantes cerca de Wangjing.
La prueba muestra claramente que LongCat-Flash no se queda “pensando” mucho tiempo antes de responder, sino que da la respuesta casi de inmediato. La búsqueda en línea también se siente “rápida”. Además, mientras responde rápido, puede citar fuentes, garantizando la credibilidad y trazabilidad de la información.
Quienes puedan descargar el modelo pueden probarlo localmente para ver si la velocidad de LongCat-Flash es igual de impresionante.
Cuando los modelos grandes entran en la era práctica
En los últimos años, cada vez que salía un modelo grande, todos se preguntaban: ¿cuáles son sus datos de benchmark? ¿Cuántos rankings ha batido? ¿Es SOTA? Ahora, la situación ha cambiado. Cuando las capacidades son similares, la gente se preocupa más por: ¿es caro de usar? ¿Qué tan rápido es? Esto es especialmente evidente entre empresas y desarrolladores que usan modelos open source. Muchos usuarios eligen modelos open source para reducir la dependencia y el costo de las APIs cerradas, por lo que son más sensibles a los requisitos de cómputo, velocidad de inferencia y efectos de compresión y cuantización.
El modelo open source LongCat-Flash de Meituan es un ejemplo de esta tendencia. Se enfocaron en cómo hacer que los modelos grandes sean realmente asequibles y rápidos, lo cual es clave para la popularización tecnológica.
Esta elección práctica coincide con la imagen que siempre tuvimos de Meituan. En el pasado, la mayoría de sus inversiones tecnológicas se destinaron a resolver problemas reales de negocio, como el artículo EDPLVO, premiado como mejor paper de navegación en ICRA 2022, que abordaba los problemas que enfrentan los drones de reparto (por ejemplo, la pérdida de señal por edificios densos); o el reciente estándar ISO global de evasión de obstáculos para drones, basado en experiencias técnicas como evitar cables de cometas o cuerdas de limpieza de ventanas. El modelo open source LongCat-Flash es, de hecho, el motor detrás de su herramienta de programación AI “NoCode”, que sirve tanto a la empresa como al público de forma gratuita, buscando que todos puedan usar el vibe coding para reducir costos y aumentar la eficiencia.
Este cambio de la competencia de rendimiento a la orientación práctica refleja la evolución natural de la industria de la IA. Cuando las capacidades de los modelos se igualan, la eficiencia de ingeniería y el costo de despliegue se convierten en factores clave de diferenciación. El open source de LongCat-Flash es solo un caso de esta tendencia, pero ofrece a la comunidad una ruta técnica de referencia: cómo, manteniendo la calidad del modelo, reducir la barrera de uso mediante innovación arquitectónica y optimización de sistemas. Para desarrolladores y empresas con presupuestos limitados pero que desean capacidades avanzadas de IA, esto es sin duda valioso.
Descargo de responsabilidad: El contenido de este artículo refleja únicamente la opinión del autor y no representa en modo alguno a la plataforma. Este artículo no se pretende servir de referencia para tomar decisiones de inversión.
También te puede gustar
¡Queda menos de un mes! La cuenta regresiva para el "cierre" del gobierno de Estados Unidos vuelve a sonar.
¡No es solo una cuestión de dinero! El caso Epstein y agentes federales, entre otros temas delicados, podrían desencadenar una crisis de cierre del gobierno estadounidense...
QuBitDEX es el patrocinador principal de la primera Cumbre Blockchain Online de Taiwán (TBOS), creando el mayor evento online de la industria en Asia.
La primera Cumbre de Blockchain en línea de Taiwán (TBOS) se llevará a cabo en septiembre de 2025, en colaboración con TBW, MYBW y otros, enfocándose en aplicaciones descentralizadas y la transición de Web2 a Web3, con el objetivo de crear el mayor evento online de Web3 en Asia. Resumen generado por Mars AI. Este resumen fue generado por el modelo Mars AI, cuya precisión y exhaustividad aún se encuentran en fase de mejora continua.

