
Lên top tìm kiếm! Mô hình AI lớn của Meituan nổi tiếng nhờ sự "nhanh chóng"

Các nhà phát triển trong và ngoài nước: Đã thử nghiệm, mô hình mã nguồn mở mới của Meituan có tốc độ siêu nhanh!
Khi AI thực sự trở nên phổ biến như nước và điện, sức mạnh của mô hình không còn là mối quan tâm duy nhất của mọi người nữa.
Từ Claude 3.7 Sonnet, Gemini 2.5 Flash đầu năm đến GPT-5, DeepSeek V3.1 gần đây, các nhà sản xuất mô hình tiên phong đều suy nghĩ: Làm thế nào để AI vừa giải quyết được từng vấn đề với lượng tính toán tối thiểu, vừa đưa ra phản hồi trong thời gian ngắn nhất mà vẫn đảm bảo độ chính xác? Nói cách khác, làm sao để vừa không lãng phí token, vừa không lãng phí thời gian.
Đối với các doanh nghiệp và nhà phát triển xây dựng ứng dụng trên mô hình, sự chuyển đổi từ "chỉ xây dựng mô hình mạnh nhất sang xây dựng mô hình thực dụng, nhanh hơn" là một tin vui. Đáng mừng hơn, các mô hình mã nguồn mở liên quan cũng ngày càng nhiều.
Vài ngày trước, chúng tôi lại phát hiện một mô hình mới trên HuggingFace ——LongCat-Flash-Chat.

Mô hình này đến từ series LongCat-Flash của Meituan, có thể sử dụng trực tiếp trên trang chủ.
Nó vốn dĩ hiểu rằng "không phải tất cả token đều như nhau", do đó sẽ phân bổ ngân sách tính toán động cho các token quan trọng dựa trên mức độ quan trọng. Nhờ vậy, chỉ cần kích hoạt một lượng nhỏ tham số, hiệu năng của nó đã có thể sánh ngang các mô hình mã nguồn mở hàng đầu hiện nay.

LongCat-Flash lên top tìm kiếm sau khi mã nguồn mở.
Đồng thời, tốc độ của mô hình này cũng để lại ấn tượng sâu sắc cho mọi người —— trên card đồ họa H800, tốc độ suy luậnvượt quá 100 token mỗi giây. Các nhà phát triển trong và ngoài nước đều xác nhận điều này —— có người đạt tốc độ 95 tokens/s, có người nhận được câu trả lời sánh ngang Claude trong thời gian ngắn nhất.
Nguồn ảnh: Người dùng Zhihu @小小将.
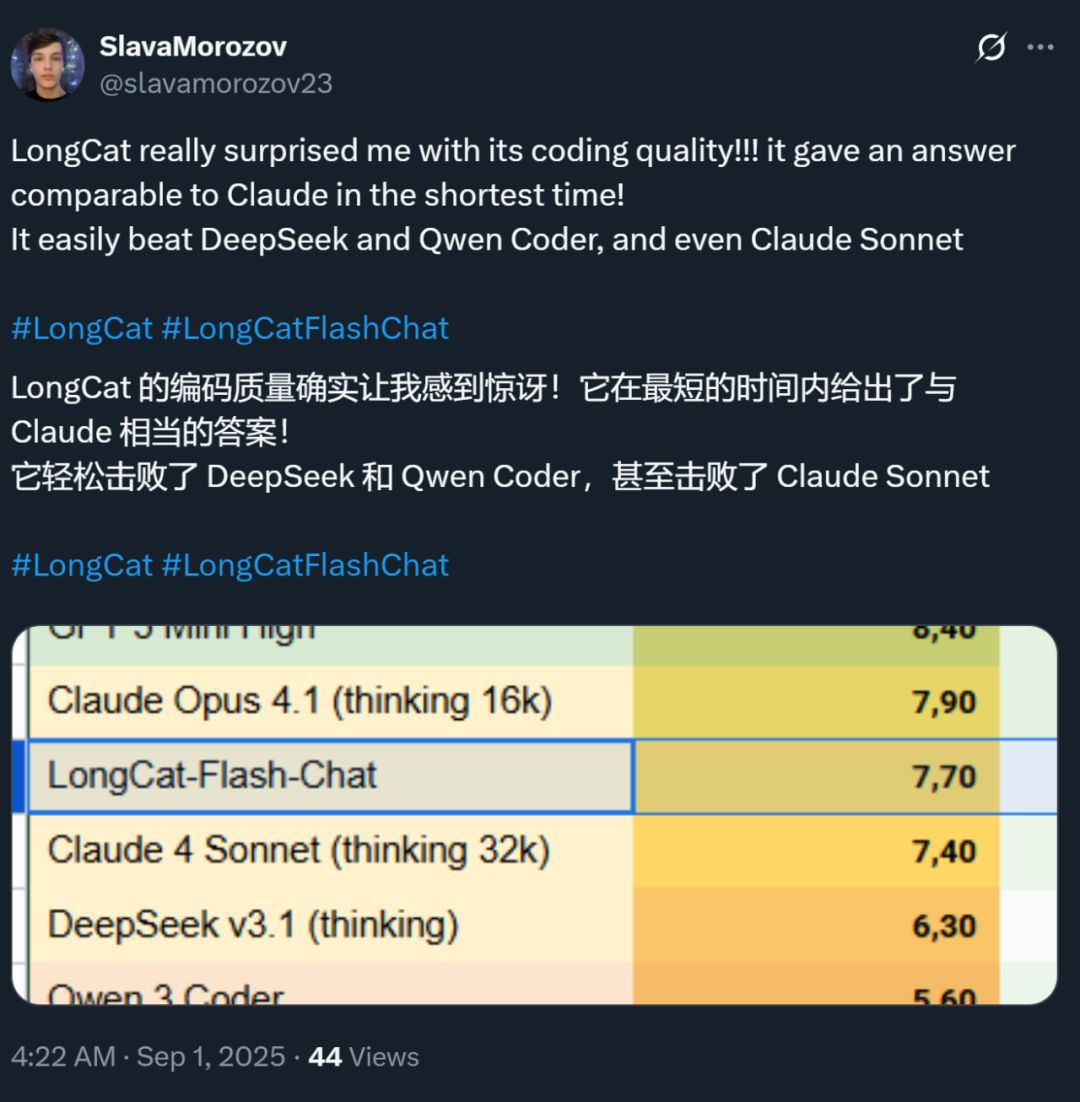
Nguồn ảnh: Người dùng X @SlavaMorozov.
Song song với việc mã nguồn mở mô hình, Meituan cũng đã công bố báo cáo kỹ thuật LongCat-Flash, trong đó có nhiều chi tiết kỹ thuật đáng chú ý.

Báo cáo kỹ thuật: LongCat-Flash Technical Report
Trong bài viết này, chúng tôi sẽ giới thiệu chi tiết.
Làm thế nào để mô hình lớn tiết kiệm tài nguyên tính toán?
Cùng xem đổi mới kiến trúc và phương pháp huấn luyện của LongCat-Flash
LongCat-Flash là mộtmô hình chuyên gia hỗn hợp, tổng số tham số là 560 billions, có thể kích hoạt18.6 billions đến 31.3 billions (trung bình 27 billions) tham số tùy theo nhu cầu ngữ cảnh.
Lượng dữ liệu dùng để huấn luyện mô hình này vượt quá 200 trillions token, nhưng thời gian huấn luyện chỉ mấtchưa đến 30 ngày. Trong thời gian này, hệ thống đạt được 98.48% thời gian khả dụng, hầu như không cần can thiệp thủ công để xử lý sự cố —— điều này có nghĩa là toàn bộ quá trình huấn luyện gần như được hoàn thành tự động "không cần người can thiệp".
Ấn tượng hơn nữa là mô hình được huấn luyện như vậy vẫn thể hiện xuất sắc khi triển khai thực tế.
Như hình dưới đây, với tư cách là mộtmô hình không thiên về tư duy, LongCat-Flash đạt đượchiệu năng tương đương với các mô hình SOTA không thiên về tư duy, bao gồm DeepSeek-V3.1 và Kimi-K2, đồng thời có ít tham số hơn và tốc độ suy luận nhanh hơn. Điều này giúp nó có tính cạnh tranh và thực tiễn cao trong các lĩnh vực tổng quát, lập trình, sử dụng công cụ agent, v.v.
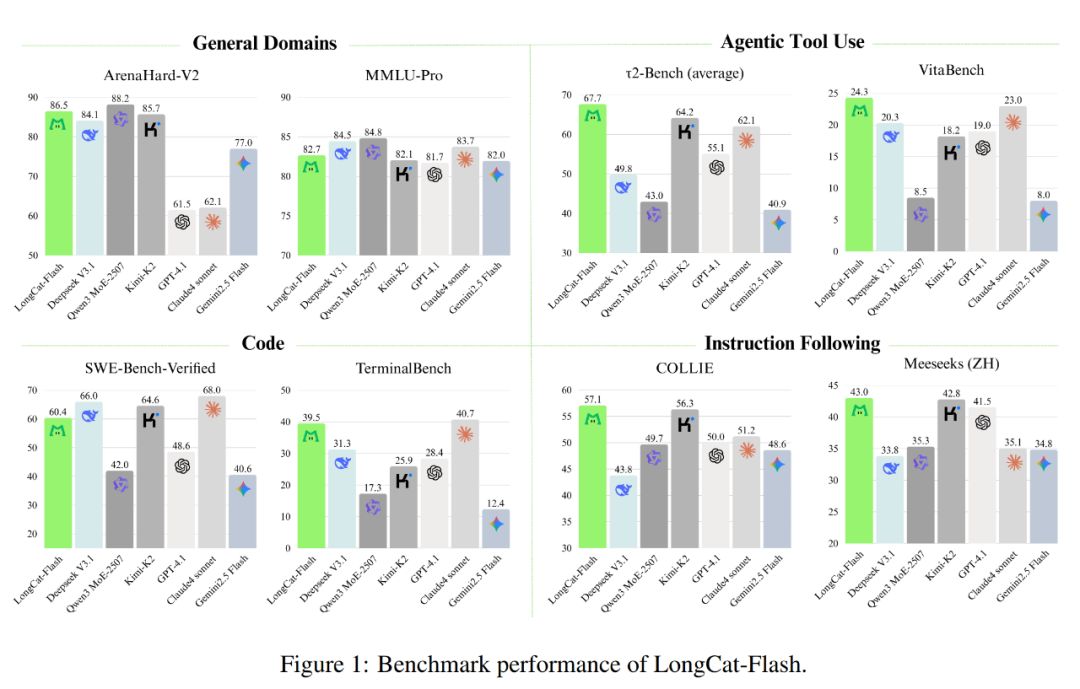
Bên cạnh đó, chi phí của nó cũng rất ấn tượng, chỉ0.7 USD cho mỗi triệu token đầu ra. Mức giá này so với các mô hình cùng quy mô trên thị trường có thể nói là rất hợp lý.
Về mặt kỹ thuật, LongCat-Flash chủ yếu nhắm đến hai mục tiêu của mô hình ngôn ngữ:hiệu quả tính toán và năng lực agent, đồng thời kết hợp đổi mới kiến trúc và phương pháp huấn luyện đa giai đoạn, từ đó xây dựng hệ thống mô hình thông minh có khả năng mở rộng.
Về kiến trúc mô hình, LongCat-Flash áp dụng một kiến trúc MoE mới lạ (hình 2), với hai điểm nổi bật:
Chuyên gia không tính toán (Zero-computation Experts);
MoE kết nối nhanh (Shortcut-connected MoE, ScMoE).
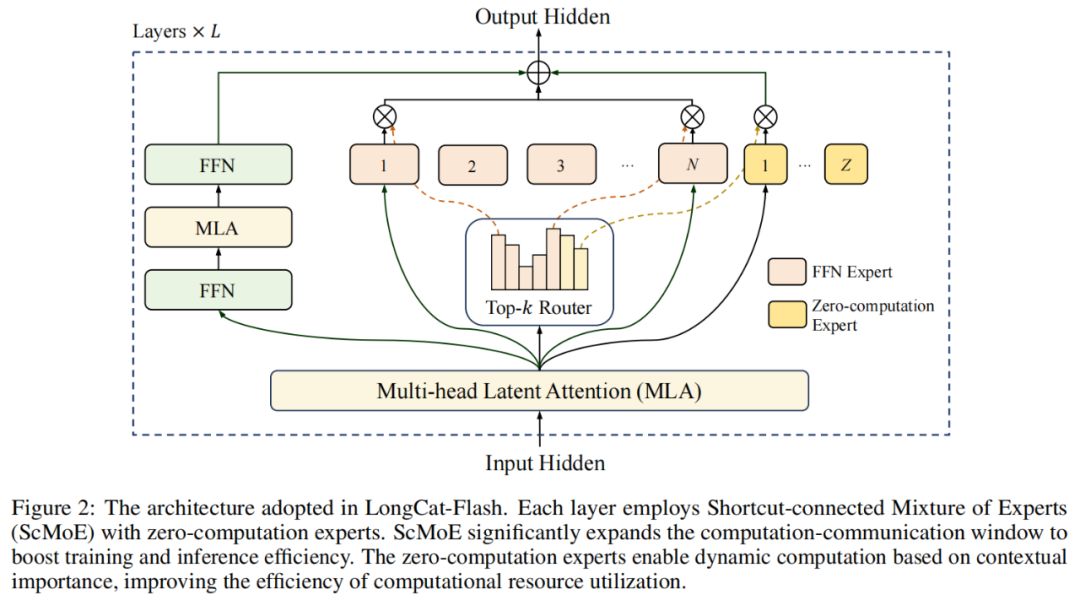
Chuyên gia không tính toán
Ý tưởng cốt lõi của chuyên gia không tính toán là không phải tất cả token đều "bình đẳng".
Có thể hiểu như sau, trong một câu, có những từ rất dễ dự đoán, như "的", "是", hầu như không cần tính toán, còn những từ như tên người thì cần nhiều tính toán để dự đoán chính xác.
Trong các nghiên cứu trước đây, mọi người thường áp dụng cách này: bất kể token đó đơn giản hay phức tạp, nó đều kích hoạt số lượng chuyên gia cố định (K), điều này gây lãng phí tính toán lớn. Với token đơn giản, không cần thiết phải gọi nhiều chuyên gia như vậy, còn với token phức tạp thì lại có thể thiếu phân bổ tính toán.
Lấy cảm hứng từ đó, LongCat-Flash đề xuất một cơ chế phân bổ tài nguyên tính toán động: thông qua chuyên gia không tính toán, kích hoạt số lượng chuyên gia FFN (Feed-Forward Network) khác nhau cho mỗi token dựa trên mức độ quan trọng của ngữ cảnh, từ đó phân bổ hợp lý hơn lượng tính toán.
Cụ thể, trong pool chuyên gia của LongCat-Flash, ngoài N chuyên gia FFN tiêu chuẩn, còn mở rộng thêm Z chuyên gia không tính toán. Chuyên gia không tính toán chỉ trả lại đầu vào như đầu ra, do đó không phát sinh thêm chi phí tính toán.
Module MoE trong LongCat-Flash có thể được biểu diễn như sau:
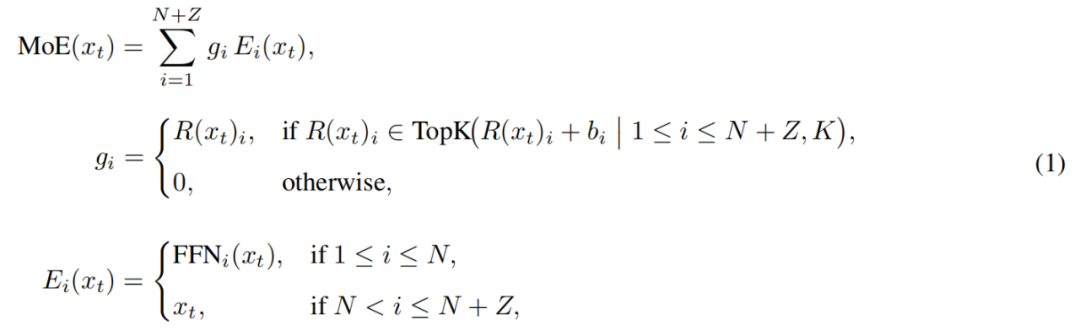
Trong đó, x_t là token thứ t trong chuỗi đầu vào, R là bộ định tuyến softmax, b_i là hệ số bias của chuyên gia thứ i, K là số chuyên gia được chọn cho mỗi token. Bộ định tuyến sẽ phân bổ mỗi token cho K chuyên gia, số lượng chuyên gia FFN được kích hoạt sẽ thay đổi tùy theo mức độ quan trọng của token trong ngữ cảnh. Thông qua cơ chế phân bổ thích ứng này, mô hình có thể học cách phân bổ nhiều tài nguyên tính toán hơn cho các token quan trọng trong ngữ cảnh, từ đó đạt hiệu năng tốt hơn với cùng lượng tính toán, như hình 3a.
Bên cạnh đó, khi xử lý đầu vào, mô hình cần học cách quyết định có nên dành nhiều tài nguyên tính toán hơn cho token quan trọng hay không. Nếu không kiểm soát tần suất chọn chuyên gia không tính toán, mô hình có thể thiên về chọn chuyên gia có tính toán, bỏ qua vai trò của chuyên gia không tính toán, dẫn đến hiệu quả tài nguyên thấp.
Để giải quyết vấn đề này, Meituan đã cải tiến cơ chế bias chuyên gia trong chiến lược aux-loss-free: bổ sung bias riêng cho từng chuyên gia, bias này có thể điều chỉnh động điểm số định tuyến dựa trên việc sử dụng chuyên gia gần đây, đồng thời vẫn tách biệt với mục tiêu huấn luyện mô hình ngôn ngữ.
Quy tắc cập nhật sử dụng bộ điều khiển PID trong lý thuyết điều khiển để điều chỉnh bias chuyên gia theo thời gian thực. Nhờ đó, khi xử lý mỗi token, mô hình chỉ cần kích hoạt 18.6 billions đến 31.3 billions (trung bình khoảng 27 billions) tham số, tối ưu hóa cấu hình tài nguyên.
MoE kết nối nhanh
Một điểm nổi bật khác của LongCat-Flash là cơ chế MoE kết nối nhanh.
Thông thường, hiệu quả của mô hình MoE quy mô lớn bị giới hạn nhiều bởi chi phí truyền thông. Trong mô hình thực thi truyền thống, chuyên gia song song sẽ tạo ra quy trình làm việc tuần tự, tức là phải thực hiện một thao tác truyền thông toàn cục để định tuyến token đến chuyên gia chỉ định, sau đó mới bắt đầu tính toán.
Quy trình tuần tự "truyền thông trước, tính toán sau" này sẽ gây ra thời gian chờ đợi bổ sung, đặc biệt trong huấn luyện phân tán quy mô lớn, độ trễ truyền thông sẽ tăng đáng kể, trở thành nút thắt hiệu năng.
Trước đây, một số nhà nghiên cứu đã sử dụng kiến trúc chuyên gia chia sẻ, cố gắng chồng lấp truyền thông với tính toán của từng chuyên gia để giảm bớt vấn đề, nhưng hiệu quả bị giới hạn bởi cửa sổ tính toán của từng chuyên gia quá nhỏ.
Meituan đã vượt qua giới hạn này bằng cách đưa vào kiến trúc ScMoE, ScMoE bổ sung một kết nối nhanh giữa các lớp, đổi mới quan trọng này giúp: tính toán FFN dày đặc của lớp trước có thể thực hiện song song với thao tác truyền thông phân phối/tổng hợp của lớp MoE hiện tại, so với kiến trúc chuyên gia chia sẻ, tạo ra cửa sổ chồng lấp truyền thông-tính toán lớn hơn nhiều.
Thiết kế kiến trúc này đã được xác nhận qua nhiều thí nghiệm.
Trước hết, thiết kế ScMoE không làm giảm chất lượng mô hình. Như hình 4, kiến trúc ScMoE và baseline không sử dụng ScMoE có đường cong mất mát huấn luyện gần như giống hệt nhau, chứng minh cách thực thi sắp xếp lại này không làm tổn hại hiệu năng mô hình. Kết luận này được xác nhận nhất quán trong nhiều cấu hình khác nhau.
Quan trọng hơn, các kết quả này cho thấy: tính ổn định và lợi thế hiệu năng của ScMoE là độc lập với lựa chọn cơ chế attention (tức là dùng attention nào cũng giữ được ổn định và lợi ích).
Tiếp theo, kiến trúc ScMoE mang lại nhiều cải tiến hiệu quả hệ thống cho cả huấn luyện và suy luận. Cụ thể:
Về huấn luyện quy mô lớn: cửa sổ chồng lấp mở rộng cho phép tính toán khối trước có thể thực hiện song song hoàn toàn với giai đoạn truyền thông phân phối và tổng hợp trong lớp MoE, điều này đạt được bằng cách chia thao tác theo chiều token thành các khối hạt mịn.
Về suy luận hiệu quả: ScMoE hỗ trợ pipeline chồng lấp đơn batch, so với các mô hình hàng đầu như DeepSeek-V3, giảm gần 50% thời gian lý thuyết mỗi token đầu ra (TPOT). Quan trọng hơn, nó cho phép thực thi đồng thời các chế độ truyền thông khác nhau: truyền thông song song tensor trong FFN dày đặc (qua NVLink) có thể chồng lấp hoàn toàn với truyền thông song song chuyên gia giữa các node (qua RDMA), tối đa hóa hiệu suất mạng tổng thể.
Tóm lại, ScMoE mang lại nhiều cải tiến hiệu năng mà không làm giảm chất lượng mô hình.
Chiến lược mở rộng mô hình và huấn luyện đa giai đoạn
Meituan còn đề xuất mộtchiến lược mở rộng mô hình hiệu quả, có thể cải thiện đáng kể hiệu năng khi mô hình mở rộng quy mô.
Đầu tiên là chuyển giao siêu tham số, khi huấn luyện mô hình siêu lớn, thử trực tiếp các cấu hình siêu tham số khác nhau rất tốn kém và không ổn định. Vì vậy, Meituan thử nghiệm trên mô hình nhỏ hơn trước, tìm ra tổ hợp siêu tham số tốt nhất, rồi chuyển các tham số này sang mô hình lớn. Nhờ đó tiết kiệm chi phí và đảm bảo hiệu quả. Quy tắc chuyển giao như bảng 1:
Tiếp theo là khởi tạo tăng trưởng mô hình (Model Growth), Meituan bắt đầu từ một mô hình nửa quy mô đã được huấn luyện trước trên hàng chục tỷ token, sau khi huấn luyện xong sẽ lưu lại checkpoint. Dựa trên đó mở rộng mô hình lên quy mô đầy đủ và tiếp tục huấn luyện.
Dựa trên cách này, mô hình thể hiện đường cong mất mát điển hình: mất mát tăng nhẹ ban đầu, sau đó hội tụ nhanh chóng và cuối cùng vượt trội rõ rệt so với baseline khởi tạo ngẫu nhiên. Hình 5b thể hiện một kết quả tiêu biểu trong thí nghiệm kích hoạt tham số 6B, cho thấy ưu thế của khởi tạo tăng trưởng mô hình.
Điểm thứ ba là bộ công cụ ổn định đa tầng, Meituan tăng cường độ ổn định huấn luyện LongCat-Flash từ ba khía cạnh: ổn định bộ định tuyến, ổn định kích hoạt và ổn định bộ tối ưu hóa.
Điểm thứ tư là tính toán xác định, phương pháp này đảm bảo kết quả thí nghiệm hoàn toàn có thể tái lập, đồng thời phát hiện lỗi hỏng dữ liệu im lặng (Silent Data Corruption, SDC) trong quá trình huấn luyện.
Nhờ các biện pháp này, quá trình huấn luyện LongCat-Flash luôn duy trì độ ổn định cao, không xuất hiện mất mát tăng vọt không thể phục hồi (loss spike).
Dựa trên nền tảng huấn luyện ổn định, Meituan cònthiết kế pipeline huấn luyện tỉ mỉ, giúp LongCat-Flash có hành vi agent cao cấp, quy trình này bao gồm huấn luyện tiền huấn luyện quy mô lớn, huấn luyện giữa kỳ tập trung vào năng lực suy luận và mã hóa, cũng như huấn luyện hậu kỳ tập trung vào hội thoại và sử dụng công cụ.
Giai đoạn đầu, xây dựng một mô hình nền tảng phù hợp hơn cho huấn luyện agent hậu kỳ, vì vậy Meituan thiết kế chiến lược hợp nhất dữ liệu tiền huấn luyện hai giai đoạn để tập trung dữ liệu lĩnh vực đòi hỏi suy luận cao.
Giữa kỳ huấn luyện, Meituan tiếp tục tăng cường năng lực suy luận và mã hóa của mô hình; đồng thời mở rộng độ dài ngữ cảnh lên 128k để đáp ứng nhu cầu huấn luyện agent hậu kỳ.
Cuối cùng, Meituan tiến hành huấn luyện hậu kỳ đa giai đoạn. Do dữ liệu huấn luyện chất lượng cao, độ khó cao trong lĩnh vực agent rất khan hiếm, Meituan thiết kế khung tổng hợp đa agent: khung này định nghĩa độ khó nhiệm vụ từ ba chiều: xử lý thông tin, độ phức tạp bộ công cụ và tương tác người dùng, sử dụng bộ điều khiển chuyên biệt để tạo ra các nhiệm vụ phức tạp cần suy luận lặp lại và tương tác môi trường.
Thiết kế này giúp mô hình thể hiện xuất sắc khi thực hiện các nhiệm vụ phức tạp cần gọi công cụ, tương tác môi trường.
Chạy vừa nhanh vừa rẻ
LongCat-Flash làm thế nào để đạt được điều đó?
Như đã đề cập, LongCat-Flash có thể suy luận với tốc độ hơn 100 token mỗi giây trên card H800, chi phí chỉ 0.7 USD cho mỗi triệu token đầu ra, có thể nói là vừa nhanh vừa rẻ.
Làm sao đạt được điều này? Đầu tiên, họ có mộtkiến trúc suy luận song song được thiết kế phối hợp với kiến trúc mô hình; thứ hai, họ còn bổ sungcác phương pháp tối ưu hóa như lượng tử hóa và kernel tùy chỉnh.
Tối ưu hóa riêng: Để mô hình "chạy mượt mà"
Chúng ta biết, để xây dựng một hệ thống suy luận hiệu quả, phải giải quyết hai vấn đề then chốt: phối hợp tính toán và truyền thông, đọc/ghi và lưu trữ bộ nhớ đệm KV.
Đối với thách thức đầu tiên, các phương pháp hiện tại thường tận dụng song song ở ba cấp độ: chồng lấp cấp toán tử, chồng lấp cấp chuyên gia và chồng lấp cấp lớp. Kiến trúc ScMoE của LongCat-Flash bổ sung chiều thứ tư —— chồng lấp cấp module. Để làm được điều này, nhóm đã thiết kếchiến lược lập lịch SBO (Single Batch Overlap) để tối ưu hóa độ trễ và thông lượng.
SBO là một phương thức pipeline bốn giai đoạn, tận dụng tối đa tiềm năng của LongCat-Flash thông qua chồng lấp cấp module, như hình 9. Khác biệt giữa SBO và TBO là SBO ẩn chi phí truyền thông trong một batch duy nhất. Giai đoạn đầu thực hiện tính toán MLA, cung cấp đầu vào cho các giai đoạn sau; giai đoạn hai chồng lấp Dense FFN và Attn 0 (QKV projection) với truyền thông all-to-all dispatch; giai đoạn ba thực hiện độc lập MoE GEMM, độ trễ hưởng lợi từ chiến lược triển khai EP rộng; giai đoạn bốn chồng lấp Attn 1 (attention cốt lõi và output projection) cùng Dense FFN với all-to-all combine. Thiết kế này giảm hiệu quả chi phí truyền thông, đảm bảo suy luận hiệu quả của LongCat-Flash.
Đối với thách thức thứ hai —— đọc/ghi và lưu trữ bộ nhớ đệm KV —— LongCat-Flash giải quyết thông qua đổi mới kiến trúc attention và cấu trúc MTP, nhằm giảm chi phí I/O hiệu quả.
Đầu tiên là tăng tốc giải mã dự đoán. LongCat-Flash sử dụng MTP làm mô hình nháp, tối ưu hóa ba yếu tố then chốt thông qua phân tích hệ thống công thức tăng tốc giải mã dự đoán: độ dài chấp nhận kỳ vọng, tỷ lệ chi phí giữa mô hình nháp và mô hình mục tiêu, cũng như tỷ lệ chi phí xác thực và giải mã mục tiêu. Bằng cách tích hợp một đầu MTP duy nhất và đưa vào ở giai đoạn cuối tiền huấn luyện, đạt tỷ lệ chấp nhận khoảng 90%. Để cân bằng chất lượng nháp và tốc độ, sử dụng kiến trúc MTP nhẹ giảm tham số, đồng thời áp dụng phương pháp C2T để lọc các token ít có khả năng được chấp nhận thông qua mô hình phân loại.
Tiếp theo là tối ưu hóa bộ nhớ đệm KV, thông qua cơ chế attention 64 đầu của MLA. MLA vừa giữ cân bằng hiệu năng và hiệu quả, vừa giảm đáng kể tải tính toán và đạt nén bộ nhớ đệm KV xuất sắc, giảm áp lực lưu trữ và băng thông. Điều này rất quan trọng để phối hợp pipeline của LongCat-Flash, vì mô hình luôn có tính toán attention không thể chồng lấp với truyền thông.
Tối ưu hóa cấp hệ thống: Để phần cứng "hợp tác nhóm"
Để giảm thiểu chi phí lập lịch, nhóm nghiên cứu LongCat-Flash đã giải quyết vấn đề launch-bound do chi phí khởi động kernel trong hệ thống suy luận LLM. Đặc biệt sau khi đưa vào giải mã dự đoán, lập lịch độc lập của kernel xác thực và forward nháp sẽ phát sinh chi phí đáng kể. Thông qua chiến lược hợp nhất TVD, họ hợp nhất forward mục tiêu, xác thực và forward nháp vào một CUDA graph duy nhất. Để tăng hiệu suất GPU, họ triển khai lập lịch chồng lấp, đồng thời đưa vào lập lịch chồng lấp nhiều bước, khởi động nhiều bước forward kernel trong một vòng lặp lập lịch, hiệu quả ẩn chi phí lập lịch và đồng bộ CPU.
Tối ưu hóa kernel tùy chỉnh nhằm vào thách thức hiệu quả đặc thù do tính chất tự hồi quy của suy luận LLM. Giai đoạn prefill đòi hỏi tính toán cao, còn giai đoạn giải mã do pattern truy cập tạo ra batch nhỏ và không đều, thường bị giới hạn bởi bộ nhớ. Đối với MoE GEMM, họ sử dụng kỹ thuật SwapAB coi trọng số như ma trận bên trái, kích hoạt như ma trận bên phải, tận dụng tính linh hoạt 8 phần tử theo chiều n để tối đa hóa hiệu suất tensor core. Kernel truyền thông sử dụng NVLink Sharp với truyền thông broadcast tăng tốc phần cứng và in-switch reduction để giảm thiểu di chuyển dữ liệu và chiếm dụng SM, chỉ cần 4 thread block đã liên tục vượt NCCL và MSCCL++ trong dải kích thước thông điệp từ 4KB đến 96MB.
Về lượng tử hóa, LongCat-Flash áp dụng phương án lượng tử hóa cấp khối hạt mịn giống DeepSeek-V3. Để đạt cân bằng tối ưu giữa hiệu năng và độ chính xác, họ triển khai lượng tử hóa hỗn hợp cấp lớp dựa trên hai phương án: phương án đầu nhận diện một số lớp tuyến tính (đặc biệt là Downproj) có đầu vào kích hoạt biên độ cực lớn tới 10^6; phương án hai tính toán lỗi lượng tử hóa FP8 cấp khối từng lớp, phát hiện lỗi lượng tử hóa đáng kể ở một số lớp chuyên gia. Lấy giao của hai phương án, đạt cải thiện độ chính xác rõ rệt.
Dữ liệu thực chiến: Chạy nhanh đến mức nào? Rẻ đến mức nào?
Kết quả thực nghiệm cho thấy, LongCat-Flash thể hiện xuất sắc trong các cấu hình khác nhau. So với DeepSeek-V3, với độ dài ngữ cảnh tương đương, LongCat-Flash đạtthông lượng sinh và tốc độ sinh cao hơn.
Trong ứng dụng Agent, xét đến nhu cầu khác biệt giữa nội dung suy luận (người dùng nhìn thấy, cần khớp tốc độ đọc của con người khoảng 20 tokens/s) và lệnh hành động (người dùng không thấy nhưng ảnh hưởng trực tiếp đến thời gian khởi động gọi công cụ, cần tốc độ tối đa), tốc độ sinh gần 100 tokens/s của LongCat-Flash giúp kiểm soát độ trễ gọi công cụ mỗi vòng trong dưới 1 giây, nâng cao đáng kể tính tương tác của ứng dụng Agent. Với giả định chi phí H800 GPU là 2 USD/giờ, điều này có nghĩa là giá mỗi triệu token đầu ra là 0.7 USD.
Phân tích hiệu năng lý thuyết cho thấy, độ trễ của LongCat-Flash chủ yếu do ba thành phần quyết định: MLA, all-to-all dispatch/combine và MoE. Với giả định EP=128, mỗi card batch=96, tỷ lệ chấp nhận MTP ≈80%, TPOT lý thuyết cực hạn của LongCat-Flash là 16ms, vượt trội so với DeepSeek-V3 là 30ms và Qwen3-235B-A22B là 26.2ms. Với giả định chi phí H800 GPU là 2 USD/giờ, chi phí đầu ra của LongCat-Flash là 0.09 USD cho mỗi triệu token, thấp hơn nhiều so với DeepSeek-V3 là 0.17 USD. Tuy nhiên, các con số này chỉ là cực hạn lý thuyết.
Trên trang trải nghiệm miễn phí LongCat-Flash, chúng tôi cũng đã thử nghiệm.
Đầu tiên, chúng tôi yêu cầu mô hình lớn này viết một bài về mùa thu, khoảng 1000 chữ.
Vừa đưa ra yêu cầu, vừa mở quay màn hình, LongCat-Flash đã viết xong câu trả lời, thậm chí chưa kịp tắt quay màn hình ngay lập tức.
Quan sát kỹ bạn sẽ thấy, tốc độ xuất token đầu tiên của LongCat-Flash đặc biệt nhanh. Trước đây dùng các mô hình hội thoại khác thường gặp cảnh chờ xoay vòng, rất thử thách sự kiên nhẫn của người dùng, giống như bạn sốt ruột xem WeChat mà điện thoại báo "đang nhận". LongCat-Flash đã thay đổi trải nghiệm này, gần như không cảm nhận được độ trễ của token đầu tiên.
Tốc độ sinh token tiếp theo cũng rất nhanh, vượt xa tốc độ đọc của mắt người.
Tiếp theo, chúng tôi bật "tìm kiếm trực tuyến", xem khả năng này của LongCat-Flash có đủ nhanh không. Chúng tôi yêu cầu LongCat-Flash gợi ý nhà hàng ngon gần Wangjing.
Kết quả thử nghiệm cho thấy rõ ràng, LongCat-Flash không phải suy nghĩ lâu mới trả lời chậm rãi, mà gần như lập tức đưa ra đáp án. Tìm kiếm trực tuyến cũng cho cảm giác "nhanh". Không chỉ vậy, nó còn trích dẫn nguồn khi trả lời nhanh, đảm bảo độ tin cậy và truy xuất thông tin.
Độc giả có điều kiện tải mô hình về có thể tự chạy thử trên máy, xem tốc độ LongCat-Flash có ấn tượng như vậy không.
Khi mô hình lớn bước vào thời đại thực dụng
Vài năm qua, mỗi khi có mô hình lớn ra mắt, mọi người đều quan tâm: dữ liệu benchmark của nó là bao nhiêu? Đã phá kỷ lục bảng xếp hạng nào? Có phải SOTA không? Hiện nay, tình hình đã thay đổi. Khi năng lực gần như tương đương, mọi người quan tâm hơn: mô hình này dùng có đắt không? Tốc độ thế nào? Đặc biệt với các doanh nghiệp và nhà phát triển dùng mô hình mã nguồn mở. Bởi nhiều người dùng mô hình mã nguồn mở là để giảm phụ thuộc và chi phí API đóng, nên càng nhạy cảm với nhu cầu tính toán, tốc độ suy luận, hiệu quả nén lượng tử hóa.
LongCat-Flash mã nguồn mở của Meituan chính là đại diện cho xu hướng này. Họ tập trung vào làm sao để mô hình lớn thực sự dùng được, chạy nhanh, đây là chìa khóa phổ cập công nghệ.
Lựa chọn hướng đi thực dụng này cũng phù hợp với ấn tượng lâu nay về Meituan. Trước đây, phần lớn đầu tư công nghệ của họ đều nhằm giải quyết bài toán thực tế, ví dụ bài báo điều hướng tốt nhất ICRA năm 2022 EDPLVO thực chất là để giải quyết các tình huống bất ngờ khi drone giao hàng (như mất tín hiệu do tòa nhà dày đặc); tiêu chuẩn ISO tránh vật cản drone toàn cầu mà họ tham gia xây dựng gần đây cũng là kết tinh kinh nghiệm kỹ thuật tránh dây diều, dây an toàn lau kính khi drone bay. Lần này, LongCat-Flash mã nguồn mở thực chất là mô hình đứng sau công cụ lập trình AI "NoCode" của họ, công cụ này vừa phục vụ nội bộ, vừa mở miễn phí cho bên ngoài, mong muốn mọi người có thể dùng vibe coding để giảm chi phí, tăng hiệu quả.
Sự chuyển đổi từ cuộc đua hiệu năng sang định hướng thực dụng thực chất phản ánh quy luật phát triển tự nhiên của ngành AI. Khi năng lực mô hình dần tiệm cận, hiệu quả kỹ thuật và chi phí triển khai trở thành yếu tố khác biệt then chốt. LongCat-Flash mã nguồn mở chỉ là một ví dụ trong xu hướng này, nhưng thực sự cung cấp cho cộng đồng một lộ trình kỹ thuật tham khảo: làm sao để giảm ngưỡng sử dụng thông qua đổi mới kiến trúc và tối ưu hóa hệ thống mà vẫn giữ chất lượng mô hình. Điều này chắc chắn có giá trị với các nhà phát triển và doanh nghiệp có ngân sách hạn chế nhưng muốn tận dụng năng lực AI tiên tiến.
Tuyên bố miễn trừ trách nhiệm: Mọi thông tin trong bài viết đều thể hiện quan điểm của tác giả và không liên quan đến nền tảng. Bài viết này không nhằm mục đích tham khảo để đưa ra quyết định đầu tư.
Bạn cũng có thể thích
WLFI chiến lược ươm tạo BlockRock, xây dựng động cơ mới cho sản phẩm phái sinh tài chính RWA
Sự hợp tác lần này không chỉ đánh dấu sự phát triển sâu rộng của WLFI trong lĩnh vực RWA mà còn khẳng định vị thế của BlockRock với tư cách là nền tảng RWA cốt lõi trong hệ sinh thái của họ.

Doanh nghiệp ra nước ngoài: Lựa chọn kiến trúc và chiến lược tối ưu hóa thuế
Kiến trúc doanh nghiệp phù hợp quan trọng đến mức nào?

Nhìn vào $HYPE để thấy sự tiến hóa trong đầu tư altcoin
Trong thời đại mà các chỉ số có thể bị thao túng, làm thế nào để xuyên thủng làn sương mù của các câu chuyện về tokenomics?
Người Hoa Malaysia bị đánh giá thấp, những người xây dựng cơ sở hạ tầng ẩn danh trong thế giới tiền mã hóa
Các cơ sở hạ tầng trong ngành crypto và những xu hướng mới như CoinGecko, Etherscan, Virtuals Protocol đều xuất phát từ các đội ngũ người Hoa tại Malaysia.
