
Em alta nas tendências! O modelo de IA da Meituan faz sucesso graças à sua “velocidade”

Desenvolvedores nacionais e internacionais: Testado pessoalmente, o novo modelo open source do Meituan é super rápido!
Quando a IA realmente se tornar tão comum quanto água e eletricidade, a força do modelo já não será a única preocupação de todos.
Desde o início do ano, com Claude 3.7 Sonnet, Gemini 2.5 Flash até os recentes GPT-5 e DeepSeek V3.1, os principais desenvolvedores de modelos estão todos pensando: como garantir que a IA, mantendo a precisão, consiga resolver cada problema com o mínimo de poder computacional e responder no menor tempo possível? Em outras palavras, como evitar desperdício de tokens e de tempo.
Para empresas e desenvolvedores que constroem aplicações sobre modelos, essa mudança de “simplesmente construir o modelo mais forte” para “construir modelos mais práticos e rápidos” é uma boa notícia. E o mais animador é que modelos open source relacionados estão se tornando cada vez mais comuns.
Há alguns dias, encontramos um novo modelo no HuggingFace — LongCat-Flash-Chat.

Este modelo vem da série LongCat-Flash do Meituan, e pode ser usado diretamente no site oficial.
Ele entende naturalmente que “nem todos os tokens são iguais”, por isso aloca dinamicamente orçamento de computação para tokens importantes de acordo com sua relevância. Isso permite que, ativando apenas um pequeno número de parâmetros, seu desempenho seja comparável aos principais modelos open source atuais.

LongCat-Flash entrou nos trending topics após ser open source.
Ao mesmo tempo, a velocidade desse modelo também impressionou — em placas H800, a velocidade de inferência ultrapassa 100 tokens por segundo. Testes de desenvolvedores nacionais e internacionais confirmaram isso — alguns atingiram 95 tokens/s, outros obtiveram respostas comparáveis ao Claude em tempo recorde.
Fonte da imagem: usuário do Zhihu @小小将.
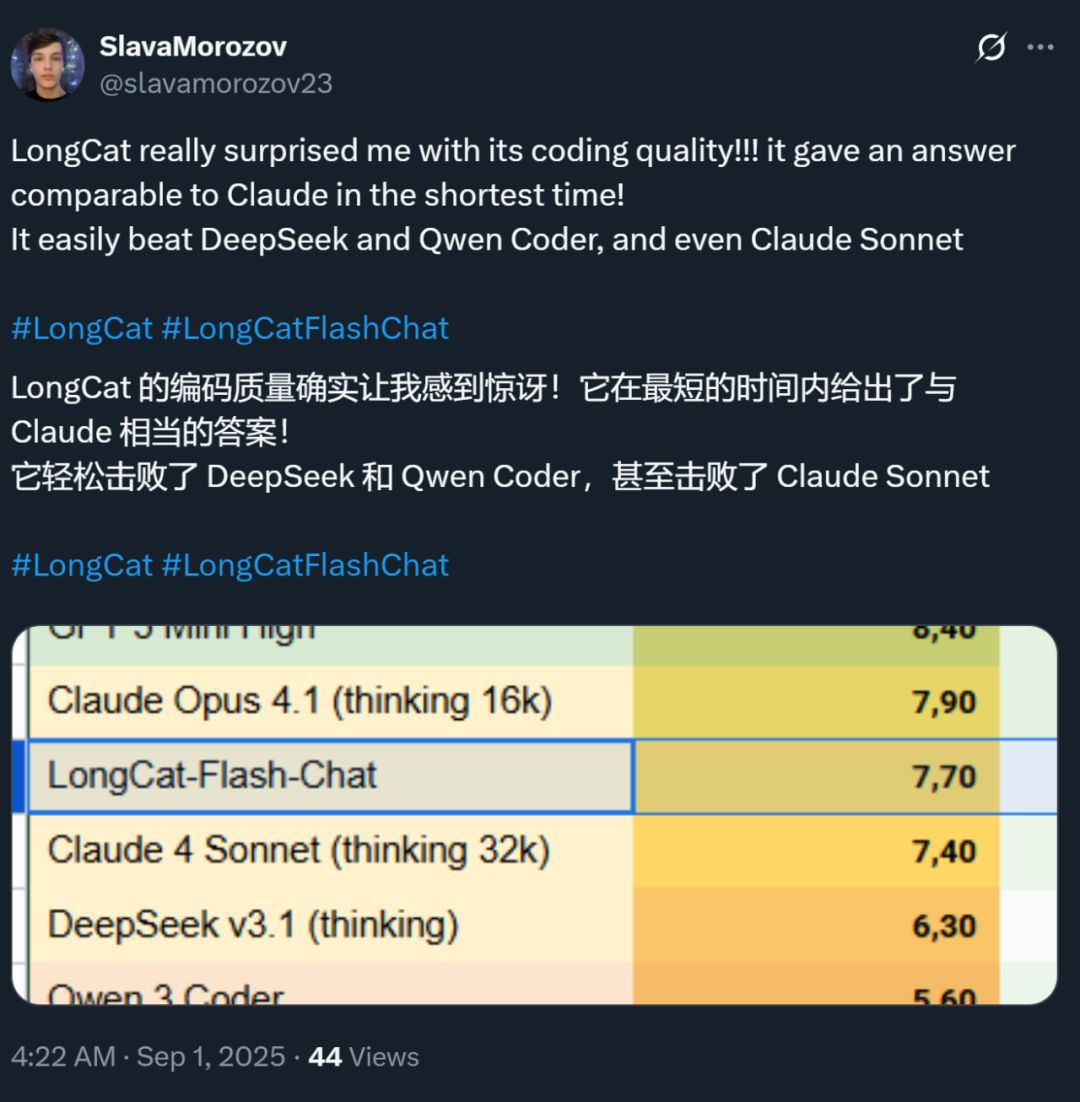
Fonte da imagem: usuário do X @SlavaMorozov.
Junto com o modelo open source, o Meituan também divulgou o relatório técnico do LongCat-Flash, onde podemos ver muitos detalhes técnicos.

Relatório técnico: LongCat-Flash Technical Report
Neste artigo, vamos detalhar.
Como grandes modelos economizam poder computacional?
Veja as inovações de arquitetura e métodos de treinamento do LongCat-Flash
LongCat-Flash é um modelo de especialistas mistos, com um total de 560 bilhões de parâmetros, podendo ativar de 18.6 bilhões a 31.3 bilhões (média de 27 bilhões) de parâmetros conforme a necessidade do contexto.
O volume de dados usado para treinar o modelo ultrapassa 20 trilhões de tokens, mas o tempo de treinamento foi de menos de 30 dias. E durante esse período, o sistema atingiu 98,48% de disponibilidade, quase sem necessidade de intervenção humana para lidar com falhas — isso significa que todo o processo de treinamento foi basicamente automático, sem intervenção.
Mais impressionante ainda é que o modelo treinado dessa forma também apresenta excelente desempenho na implantação real.
Como mostrado abaixo, como um modelo não reflexivo, o LongCat-Flash atingiu desempenho equivalente aos SOTA modelos não reflexivos, incluindo DeepSeek-V3.1 e Kimi-K2, com menos parâmetros e velocidade de inferência mais rápida. Isso o torna bastante competitivo e prático em áreas como uso geral, programação e ferramentas de agentes inteligentes.
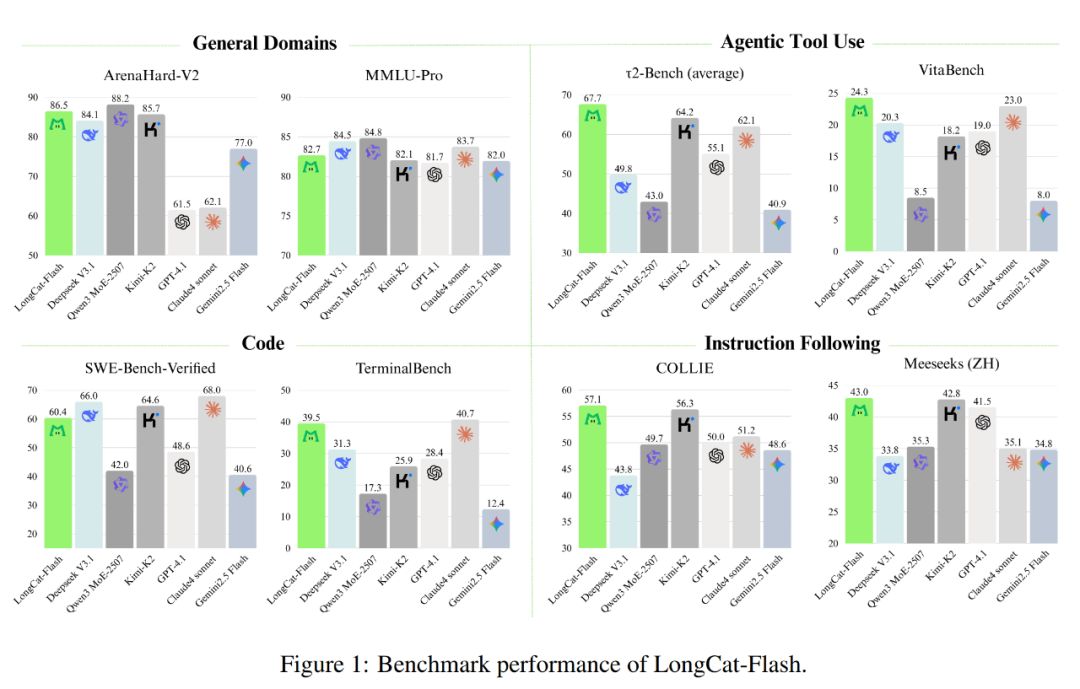
Além disso, seu custo também chama atenção, sendo de apenas 0,7 dólares por milhão de tokens gerados. Esse preço é muito competitivo em relação a modelos de escala semelhante no mercado.
Tecnologicamente, o LongCat-Flash foca em dois objetivos dos modelos de linguagem: eficiência computacional e capacidade de agente inteligente, integrando inovações de arquitetura e métodos de treinamento em múltiplas etapas para criar um sistema de modelo escalável e inteligente.
Na arquitetura do modelo, o LongCat-Flash adota uma nova arquitetura MoE (Figura 2), com dois destaques:
Especialistas de zero computação (Zero-computation Experts);
MoE com conexão rápida (Shortcut-connected MoE, ScMoE).
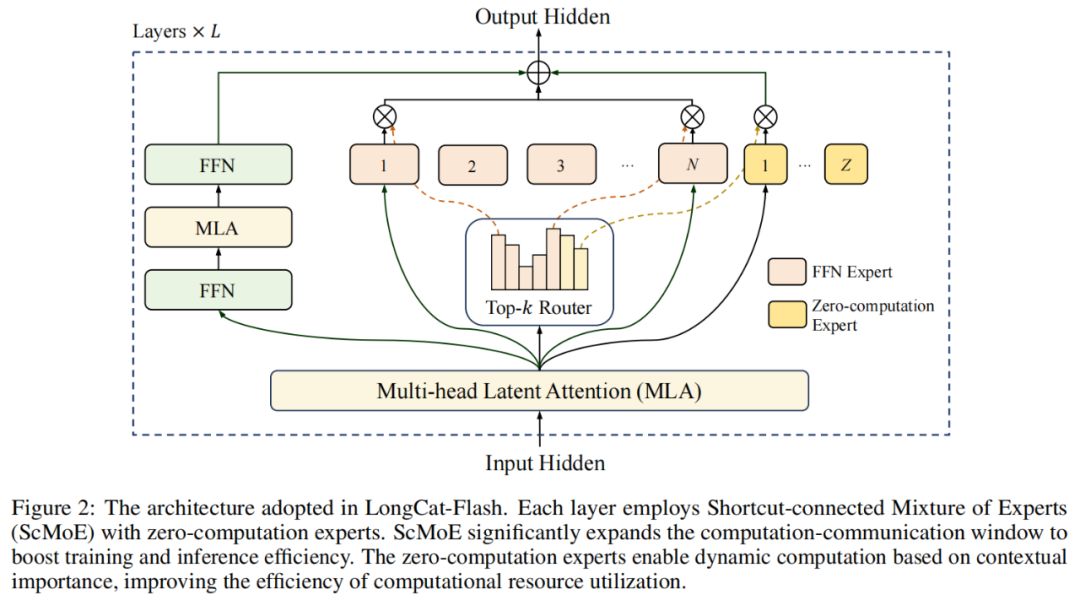
Especialistas de zero computação
A ideia central dos especialistas de zero computação é que nem todos os tokens são “iguais”.
Podemos entender assim: em uma frase, algumas palavras são muito fáceis de prever, como “de”, “é”, quase não exigem computação, enquanto outras, como nomes próprios, exigem muito mais computação para serem previstas corretamente.
Em pesquisas anteriores, normalmente se adotava o seguinte: independentemente de o token ser simples ou complexo, ele ativava um número fixo (K) de especialistas, o que gerava grande desperdício computacional. Para tokens simples, não há necessidade de chamar tantos especialistas, enquanto para tokens complexos, pode faltar alocação suficiente de computação.
Inspirado nisso, o LongCat-Flash propôs um mecanismo dinâmico de alocação de recursos computacionais: por meio dos especialistas de zero computação, ativa dinamicamente diferentes quantidades de especialistas FFN (Feed-Forward Network) para cada token, alocando computação de forma mais racional conforme a importância do contexto.
Especificamente, no pool de especialistas do LongCat-Flash, além dos N especialistas FFN padrão, foram adicionados Z especialistas de zero computação. Estes apenas retornam a entrada como saída, sem custo computacional adicional.
O módulo MoE do LongCat-Flash pode ser formalizado como:
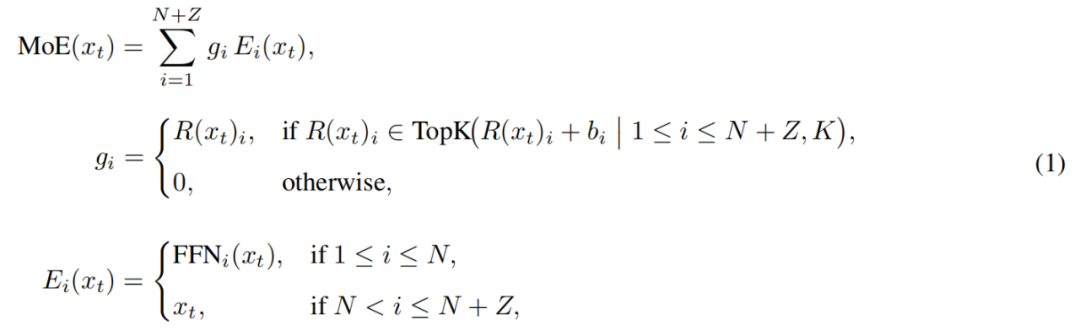
Onde x_t é o t-ésimo token da sequência de entrada, R representa o roteador softmax, b_i é o viés do i-ésimo especialista, e K é o número de especialistas selecionados por token. O roteador aloca cada token para K especialistas, e o número de especialistas FFN ativados varia conforme a importância contextual do token. Com esse mecanismo adaptativo, o modelo aprende a alocar mais recursos computacionais para tokens mais importantes, otimizando o desempenho sob o mesmo volume de computação, como mostrado na Figura 3a.
Além disso, ao processar a entrada, o modelo precisa aprender a decidir, conforme a importância do token, se vale a pena gastar mais recursos computacionais. Se não controlar a frequência de seleção dos especialistas de zero computação, o modelo pode tender a escolher especialistas com computação, ignorando os de zero computação, reduzindo a eficiência dos recursos.
Para resolver isso, o Meituan aprimorou o mecanismo de viés de especialista na estratégia aux-loss-free: introduziu um viés específico para cada especialista, que ajusta dinamicamente a pontuação de roteamento conforme o uso recente do especialista, mantendo-se desacoplado do objetivo de treinamento do modelo de linguagem.
A regra de atualização usa um controlador PID da teoria de controle para ajustar em tempo real o viés dos especialistas. Assim, ao processar cada token, o modelo só precisa ativar de 18.6 bilhões a 31.3 bilhões (média de cerca de 27 bilhões) de parâmetros, otimizando a alocação de recursos.
MoE com conexão rápida
Outro destaque do LongCat-Flash é o mecanismo MoE com conexão rápida.
Em geral, a eficiência de grandes modelos MoE é bastante limitada pelo custo de comunicação. No paradigma tradicional, a execução paralela dos especialistas introduz um fluxo de trabalho sequencial: primeiro, é preciso uma operação de comunicação global para rotear os tokens para seus especialistas designados, só então o cálculo pode começar.
Essa sequência de comunicação e depois computação gera tempo de espera extra, especialmente em treinamento distribuído em larga escala, onde a latência de comunicação pode se tornar um gargalo de desempenho.
Pesquisadores anteriores tentaram usar arquiteturas de especialistas compartilhados para sobrepor comunicação e computação de um único especialista, mas a eficiência era limitada pela pequena janela de computação do especialista.
O Meituan superou essa limitação com a arquitetura ScMoE, que introduz uma conexão rápida entre camadas, permitindo que o cálculo do FFN denso da camada anterior ocorra em paralelo com a comunicação de distribuição/agregação da camada MoE atual. Comparado à arquitetura de especialistas compartilhados, isso cria uma janela de sobreposição comunicação-computação muito maior.
Esse design foi validado em vários experimentos.
Primeiro, o design ScMoE não reduz a qualidade do modelo. Como mostrado na Figura 4, a curva de perda de treinamento do ScMoE é praticamente idêntica à da linha de base sem ScMoE, provando que essa reordenação de execução não prejudica o desempenho do modelo. Isso foi confirmado em várias configurações.
Mais importante, esses resultados mostram que a estabilidade e o desempenho do ScMoE são ortogonais à escolha do mecanismo de atenção (ou seja, qualquer mecanismo de atenção mantém estabilidade e ganhos).
Segundo, a arquitetura ScMoE oferece grandes ganhos de eficiência sistêmica para treinamento e inferência. Especificamente:
No treinamento em larga escala: a janela de sobreposição expandida permite que o cálculo dos blocos anteriores ocorra totalmente em paralelo com as fases de comunicação de distribuição e agregação da camada MoE, dividindo as operações em blocos de granularidade fina ao longo da dimensão do token.
Na inferência eficiente: o ScMoE suporta pipeline de sobreposição em lote único, reduzindo o tempo teórico por token (TPOT) em quase 50% em relação a modelos líderes como DeepSeek-V3. Mais importante, permite execução concorrente de diferentes modos de comunicação: a comunicação paralela de tensores dentro do nó no FFN denso (via NVLink) pode ser totalmente sobreposta à comunicação paralela de especialistas entre nós (via RDMA), maximizando a utilização da rede.
Em resumo, o ScMoE oferece grandes ganhos de desempenho sem sacrificar a qualidade do modelo.
Estratégia de expansão do modelo e treinamento em múltiplas etapas
O Meituan também propôs uma estratégia eficiente de expansão do modelo, melhorando significativamente o desempenho à medida que o modelo cresce.
Primeiro, a transferência de hiperparâmetros: ao treinar modelos de escala ultra grande, testar diretamente várias configurações de hiperparâmetros é caro e instável. O Meituan primeiro experimenta em modelos menores para encontrar a melhor combinação de hiperparâmetros e depois transfere esses parâmetros para o modelo grande, economizando custos e garantindo resultados. As regras de transferência estão na Tabela 1:
Depois, a inicialização por crescimento do modelo: o Meituan começa com um modelo de meia escala pré-treinado em dezenas de bilhões de tokens, salva o checkpoint, expande para a escala completa e continua o treinamento.
Com esse método, o modelo apresenta uma curva de perda típica: a perda sobe brevemente, depois converge rapidamente e supera significativamente a linha de base com inicialização aleatória. A Figura 5b mostra um resultado representativo do experimento com 6B parâmetros ativados, destacando a vantagem da inicialização por crescimento.
Terceiro, um kit de estabilidade em múltiplos níveis: o Meituan reforçou a estabilidade do treinamento do LongCat-Flash em três aspectos — roteador, ativação e otimizador.
Quarto, computação determinística: esse método garante total reprodutibilidade dos resultados experimentais e detecta corrupção silenciosa de dados (Silent Data Corruption, SDC) durante o treinamento.
Com essas medidas, o treinamento do LongCat-Flash permanece altamente estável, sem picos de perda irrecuperáveis.
Com a estabilidade do treinamento garantida, o Meituan também projetou cuidadosamente o pipeline de treinamento, dotando o LongCat-Flash de comportamentos avançados de agente inteligente, abrangendo pré-treinamento em larga escala, treinamento intermediário focado em raciocínio e código, e pós-treinamento voltado para diálogo e uso de ferramentas.
Na fase inicial, constrói-se um modelo base mais adequado para pós-treinamento de agentes inteligentes; para isso, o Meituan projetou uma estratégia de fusão de dados de pré-treinamento em duas etapas, focando em dados de áreas intensivas em raciocínio.
No meio do treinamento, o Meituan reforça ainda mais a capacidade de raciocínio e código do modelo; ao mesmo tempo, expande o comprimento do contexto para 128k, atendendo às necessidades do pós-treinamento de agentes inteligentes.
Por fim, o Meituan realiza pós-treinamento em múltiplas etapas. Dada a escassez de dados de treinamento de alta qualidade e alta dificuldade para agentes inteligentes, o Meituan projetou uma estrutura de síntese multiagente: define a dificuldade das tarefas em três dimensões — processamento de informação, complexidade do conjunto de ferramentas e interação com o usuário — usando um controlador dedicado para gerar tarefas complexas que exigem raciocínio iterativo e interação com o ambiente.
Esse design faz com que o modelo se destaque em tarefas complexas que exigem uso de ferramentas e interação com o ambiente.
Rápido e barato na prática
Como o LongCat-Flash consegue isso?
Como mencionado, o LongCat-Flash pode inferir a mais de 100 tokens por segundo em placas H800, com custo de apenas 0,7 dólares por milhão de tokens gerados — ou seja, é rápido e barato.
Como isso é possível? Primeiro, eles têm uma arquitetura de inferência paralela co-projetada com a arquitetura do modelo; segundo, incorporaram métodos de otimização como quantização e kernels customizados.
Otimização dedicada: deixando o modelo “rodar suavemente”
Sabemos que, para construir um sistema de inferência eficiente, é preciso resolver dois problemas-chave: a coordenação entre computação e comunicação, e a leitura/escrita e armazenamento do cache KV.
Para o primeiro desafio, os métodos existentes geralmente exploram paralelismo em três níveis: sobreposição a nível de operador, de especialista e de camada. A arquitetura ScMoE do LongCat-Flash introduz um quarto nível — sobreposição a nível de módulo. Para isso, a equipe projetou a estratégia SBO (Single Batch Overlap) para otimizar latência e throughput.
SBO é uma execução em pipeline de quatro estágios, aproveitando ao máximo o potencial do LongCat-Flash com sobreposição a nível de módulo, como mostrado na Figura 9. A diferença entre SBO e TBO é que SBO esconde o custo de comunicação dentro de um único batch. No primeiro estágio, executa o cálculo MLA, fornecendo entrada para os estágios seguintes; no segundo, sobrepõe Dense FFN e Attn 0 (projeção QKV) com a comunicação all-to-all dispatch; no terceiro, executa MoE GEMM independentemente, beneficiando-se da estratégia de implantação EP; no quarto, sobrepõe Attn 1 (atenção central e projeção de saída) e Dense FFN com all-to-all combine. Esse design reduz efetivamente o custo de comunicação, garantindo inferência eficiente do LongCat-Flash.
Para o segundo desafio — leitura/escrita e armazenamento do cache KV — o LongCat-Flash resolve por meio de inovações na arquitetura de atenção e estrutura MTP, reduzindo o custo efetivo de I/O.
Primeiro, aceleração por decodificação especulativa. O LongCat-Flash usa MTP como modelo rascunho, otimizando três fatores-chave por meio de análise sistêmica da fórmula de aceleração da decodificação especulativa: comprimento de aceitação esperado, razão de custo entre modelo rascunho e alvo, e razão de custo entre validação e decodificação do alvo. Integrando uma única cabeça MTP e introduzindo-a no final do pré-treinamento, alcançou cerca de 90% de taxa de aceitação. Para equilibrar qualidade e velocidade do rascunho, adota arquitetura MTP leve para reduzir parâmetros e usa o método C2T para filtrar tokens improváveis via modelo de classificação.
Segundo, otimização do cache KV, por meio do mecanismo de atenção de 64 cabeças do MLA. O MLA equilibra desempenho e eficiência, reduzindo significativamente a carga computacional e alcançando excelente compressão do cache KV, aliviando pressão de armazenamento e banda. Isso é crucial para coordenar o pipeline do LongCat-Flash, pois o modelo sempre tem cálculos de atenção que não podem ser sobrepostos à comunicação.
Otimização sistêmica: fazendo o hardware “trabalhar em equipe”
Para minimizar o custo de agendamento, a equipe do LongCat-Flash resolveu o problema de launch-bound causado pelo overhead de inicialização do kernel em sistemas de inferência LLM. Especialmente após introduzir decodificação especulativa, o agendamento independente do kernel de validação e do forward do rascunho gera overhead significativo. Com a estratégia de fusão TVD, eles fundiram forward alvo, validação e forward do rascunho em um único gráfico CUDA. Para aumentar ainda mais o uso da GPU, implementaram um agendador sobreposto e introduziram um agendador de sobreposição multi-etapas, lançando múltiplos kernels de forward em uma única iteração de agendamento, escondendo efetivamente o overhead de agendamento e sincronização da CPU.
Kernels customizados otimizam desafios de eficiência únicos trazidos pela natureza autoregressiva da inferência LLM. A fase de pré-preenchimento é intensiva em computação, enquanto a fase de decodificação, devido ao padrão de tráfego, gera batches pequenos e irregulares, geralmente limitados por memória. Para MoE GEMM, usaram a técnica SwapAB, tratando pesos como matriz da esquerda e ativações como matriz da direita, maximizando o uso do tensor core com granularidade de 8 elementos na dimensão n. O kernel de comunicação usa o broadcast acelerado por hardware do NVLink Sharp e redução in-switch para minimizar movimentação de dados e ocupação de SM, superando consistentemente NCCL e MSCCL++ com apenas 4 blocos de threads em mensagens de 4KB a 96MB.
Na quantização, o LongCat-Flash adota o mesmo esquema de quantização em blocos de granularidade fina do DeepSeek-V3. Para o melhor equilíbrio desempenho-precisão, implementa quantização mista por camada baseada em dois esquemas: o primeiro identifica camadas lineares (especialmente Downproj) cujas ativações de entrada atingem amplitude extrema de até 10^6; o segundo calcula erro de quantização FP8 por bloco em cada camada, encontrando erros significativos em camadas de especialistas específicas. Tomando a interseção dos dois esquemas, obteve-se ganho significativo de precisão.
Dados práticos: quão rápido? Quão barato?
O desempenho real mostra que o LongCat-Flash se destaca em diferentes configurações. Comparado ao DeepSeek-V3, com contexto semelhante, o LongCat-Flash atinge maior throughput e velocidade de geração.
Em aplicações de Agent, considerando as diferentes necessidades de inferência (conteúdo visível ao usuário, que deve corresponder à velocidade de leitura humana, cerca de 20 tokens/s, e comandos de ação, invisíveis ao usuário mas que afetam diretamente o tempo de chamada de ferramentas, exigindo máxima velocidade), a velocidade de geração de quase 100 tokens/s do LongCat-Flash mantém a latência de chamada de ferramenta por rodada em menos de 1 segundo, melhorando significativamente a interatividade das aplicações Agent. Supondo um custo de 2 dólares por hora para GPU H800, isso significa um preço de 0,7 dólares por milhão de tokens gerados.
Análises teóricas mostram que a latência do LongCat-Flash é determinada por três componentes: MLA, all-to-all dispatch/combine e MoE. Com EP=128, batch por placa=96, taxa de aceitação MTP≈80%, o TPOT teórico do LongCat-Flash é de 16ms, bem melhor que os 30ms do DeepSeek-V3 e 26,2ms do Qwen3-235B-A22B. Supondo GPU H800 a 2 dólares/hora, o custo de saída do LongCat-Flash é de 0,09 dólares por milhão de tokens, bem abaixo dos 0,17 dólares do DeepSeek-V3. No entanto, esses valores são limites teóricos.
Na página de teste gratuito do LongCat-Flash, também fizemos um teste.
Primeiro, pedimos ao modelo para escrever um texto sobre o outono, com cerca de 1000 caracteres.
Assim que fizemos o pedido e começamos a gravar a tela, o LongCat-Flash já havia escrito a resposta — nem deu tempo de parar a gravação a tempo.
Observando atentamente, percebe-se que a velocidade de saída do primeiro token do LongCat-Flash é especialmente rápida. Em outros modelos de diálogo, é comum esperar com a tela carregando, testando a paciência do usuário — como quando você quer ver uma mensagem no WeChat e o celular mostra “recebendo”. O LongCat-Flash muda essa experiência, praticamente eliminando a latência do primeiro token.
A geração dos tokens seguintes também é muito rápida, superando de longe a velocidade de leitura humana.
Em seguida, ativamos a “busca online” para ver se o LongCat-Flash é rápido nessa função. Pedimos recomendações de bons restaurantes perto de Wangjing.
No teste, ficou claro que o LongCat-Flash não demora para “pensar” antes de responder, mas praticamente responde instantaneamente. A busca online também é “rápida”. Além disso, ao fornecer respostas rápidas, ainda cita as fontes, garantindo credibilidade e rastreabilidade das informações.
Quem puder baixar o modelo pode rodar localmente e ver se a velocidade do LongCat-Flash é igualmente impressionante.
Quando os grandes modelos entram na era da utilidade
Nos últimos anos, sempre que surgia um grande modelo, todos se perguntavam: qual é o benchmark? Quantos rankings ele quebrou? É SOTA? Agora, a situação mudou. Com capacidades semelhantes, o que importa é: esse modelo é caro? É rápido? Entre empresas e desenvolvedores que usam modelos open source, isso é ainda mais evidente. Muitos usam modelos open source para reduzir dependência e custos de APIs proprietárias, por isso são mais sensíveis a requisitos de poder computacional, velocidade de inferência e eficiência de compressão/quantização.
O LongCat-Flash open source do Meituan é um exemplo dessa tendência. O foco foi em tornar o grande modelo realmente acessível e rápido — um ponto-chave para a popularização da tecnologia.
Essa escolha prática está alinhada com a imagem do Meituan. No passado, a maior parte dos investimentos em tecnologia foi para resolver problemas reais de negócios, como o EDPLVO, vencedor do prêmio de melhor artigo de navegação no ICRA 2022, criado para lidar com imprevistos em entregas de drones (como perda de sinal em áreas densamente construídas); ou a recente participação na formulação do padrão ISO global de desvio de obstáculos para drones, baseada em experiências técnicas como evitar linhas de pipa ou cordas de limpeza de janelas. O LongCat-Flash open source é, na verdade, o modelo por trás da ferramenta de programação AI “NoCode” do Meituan, que serve tanto para uso interno quanto externo, gratuitamente, para promover o vibe coding e aumentar eficiência e reduzir custos.
Essa mudança de competição por desempenho para foco na utilidade reflete a evolução natural da indústria de IA. À medida que as capacidades dos modelos se nivelam, eficiência de engenharia e custo de implantação tornam-se fatores diferenciais. O open source do LongCat-Flash é apenas um caso desse movimento, mas oferece à comunidade um caminho técnico de referência: como, mantendo a qualidade do modelo, inovar na arquitetura e otimizar o sistema para reduzir barreiras de uso. Para desenvolvedores e empresas com orçamento limitado, mas que desejam usar IA avançada, isso é sem dúvida valioso.
Aviso Legal: o conteúdo deste artigo reflete exclusivamente a opinião do autor e não representa a plataforma. Este artigo não deve servir como referência para a tomada de decisões de investimento.
Talvez também goste
Quando ouvimos previsões de que o Bitcoin chegará a 1 milhão, mas vemos a realidade de preços caindo constantemente, em quem devemos acreditar?
As pessoas não falam mais sobre autocustódia ou discussões cypherpunk sobre bitcoin; agora o foco está em grandes figuras políticas e engenharia financeira.

Taxas de gas caem 60%! O custo de interação com DApps diminui significativamente, acelerando o crescimento do ecossistema TRON.
A TRON não só implementou uma redução histórica de até 60% nas taxas de Gas, como também introduziu um mecanismo de ajuste dinâmico trimestral.
BitsLabAI Scanner supera vários auditores em competição de auditoria e conquista o segundo lugar
O BitslabAI Scanner utilizou um scanner impulsionado por IA para superar a maioria dos auditores em uma competição de auditoria.

Opinião: O verdadeiro valor das L2s é ser um “laboratório experimental de inovação”
Abandonar a abordagem abrangente das General-Purpose Chains e explorar Specific-Chains voltadas para as novas demandas de Mass Adoption é o caminho correto.