
話題急上昇!Meituanの大規模モデル、「速さ」で人気爆発

国内外の開発者:実際に試してみたところ、Meituanの新しいオープンソースモデルは超高速!
AIが本当に水や電気のように普及した後は、モデルの強さだけが唯一の関心事ではなくなりました。
年初のClaude 3.7 Sonnet、Gemini 2.5 Flashから、最近のGPT-5、DeepSeek V3.1まで、先端を行くモデルベンダーは皆、「正確性を保証しつつ、いかに最小限の計算リソースで問題を解決し、最短時間で応答を返すか?」を考えています。言い換えれば、「tokenも時間も無駄にしない」方法を模索しているのです。
モデル上でアプリケーションを構築する企業や開発者にとって、「単に最強のモデルを作る」から「より実用的で高速なモデルを作る」への転換は朗報です。さらに嬉しいのは、関連するオープンソースモデルも徐々に増えてきていることです。
数日前、私たちはHuggingFaceで新しいモデル——LongCat-Flash-Chatを発見しました。

このモデルはMeituanのLongCat-Flashシリーズに由来し、公式サイトで直接利用できます。
このモデルは「not all tokens are equal(すべてのtokenが等価ではない)」ということを自然に理解しており、重要度に応じて重要なtokenに動的な計算予算を割り当てます。これにより、少数のパラメータのみをアクティブにしても、現在の先進的なオープンソースモデルと肩を並べる性能を発揮できます。

LongCat-Flashのオープンソース化後、トレンド入り。
同時に、このモデルの速度も多くの人に強い印象を残しました——H800 GPU上での推論速度は毎秒100token超。国内外の開発者による実測でもこれが証明されています——95tokens/sを記録した人もいれば、最短時間でClaudeに匹敵する回答を得た人もいます。
画像出典:Zhihuユーザー @小小将。
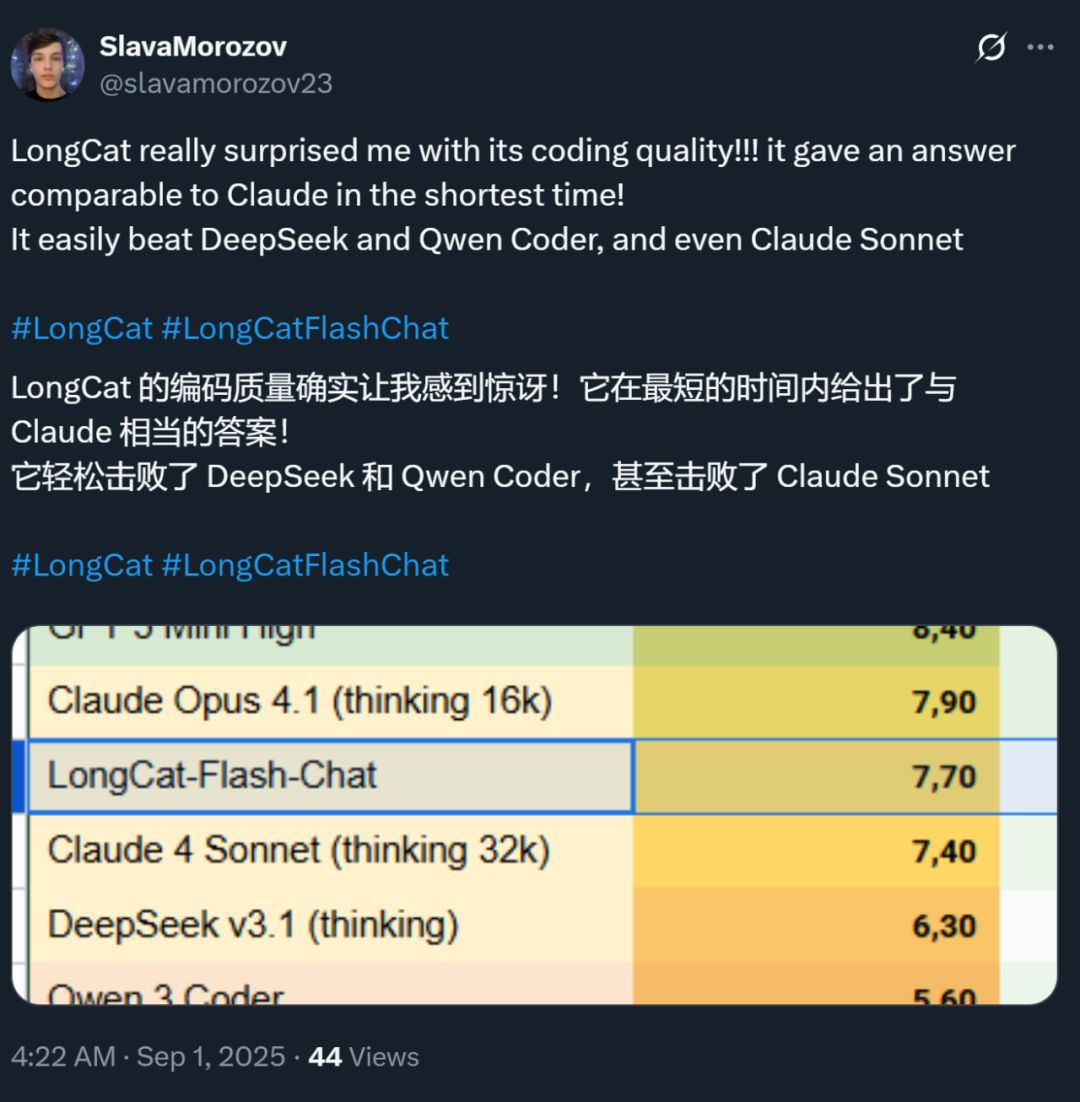
画像出典:Xユーザー @SlavaMorozov。
オープンソースモデルの公開と同時に、MeituanはLongCat-Flashの技術レポートも公開しており、多くの技術的詳細が確認できます。

技術レポート:LongCat-Flash Technical Report
この記事では、その詳細を紹介します。
大規模モデルはどうやって計算リソースを節約する?
LongCat-Flashのアーキテクチャ革新とトレーニング手法を見てみよう
LongCat-Flashは混合エキスパートモデルで、総パラメータ数は560 billions、文脈の要求に応じて18.6 billionsから31.3 billions(平均27 billions)のパラメータをアクティブにできます。
このモデルのトレーニングに使われたデータ量は20兆tokenを超えますが、トレーニング期間は30日未満。しかもこの期間、システムの98.48%の時間が利用可能で、ほぼ人手による障害対応が不要——つまり、トレーニング全体がほぼ「無人介入」で自動完了したことを意味します。
さらに印象的なのは、このようにトレーニングされたモデルが実際のデプロイ時にも同様に優れたパフォーマンスを発揮することです。
下図のように、非思考型モデルとして、LongCat-FlashはSOTA非思考型モデルと同等の性能を達成しています(DeepSeek-V3.1やKimi-K2など)。しかもパラメータ数が少なく、推論速度も速い。これにより、汎用、プログラミング、エージェントツール利用などの分野で競争力と実用性を備えています。
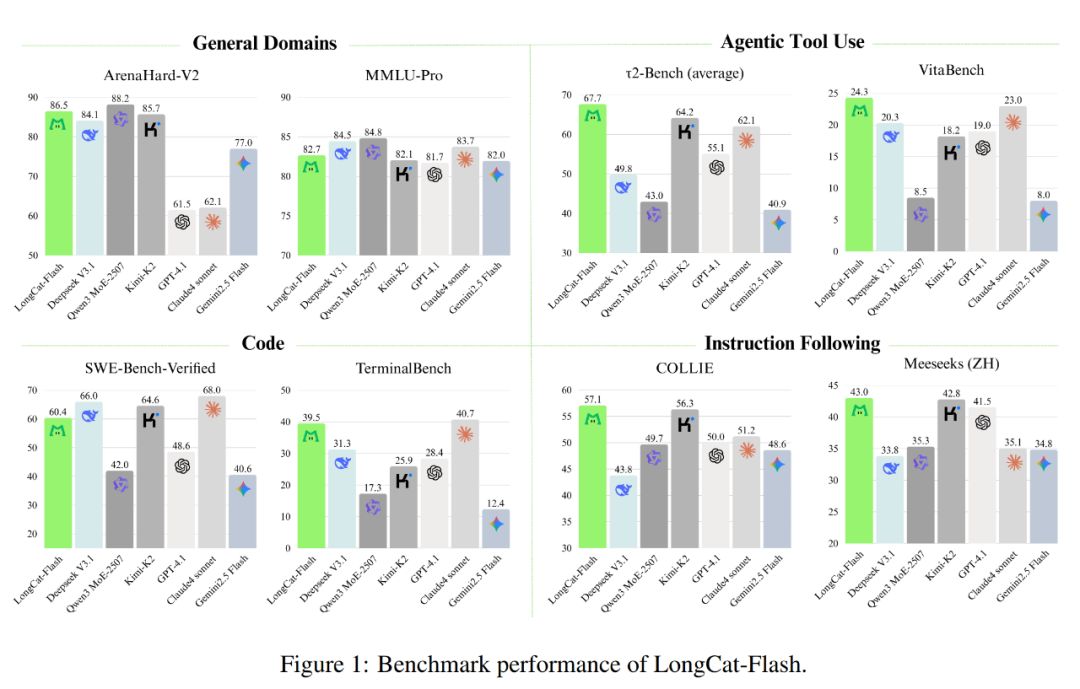
さらにコスト面でも優れており、100万出力tokenあたり0.7ドル。この価格は同規模の他モデルと比べても非常にリーズナブルです。
技術的には、LongCat-Flashは主に言語モデルの2つの目標:計算効率とエージェント能力に焦点を当て、アーキテクチャの革新と多段階トレーニング手法を融合し、拡張性と知能を兼ね備えたモデル体系を実現しています。
モデルアーキテクチャ面では、LongCat-Flashは新しいMoEアーキテクチャ(図2)を採用し、主な特徴は以下の2点です:
ゼロ計算エキスパート(Zero-computation Experts)
ショートカット接続MoE(Shortcut-connected MoE、ScMoE)
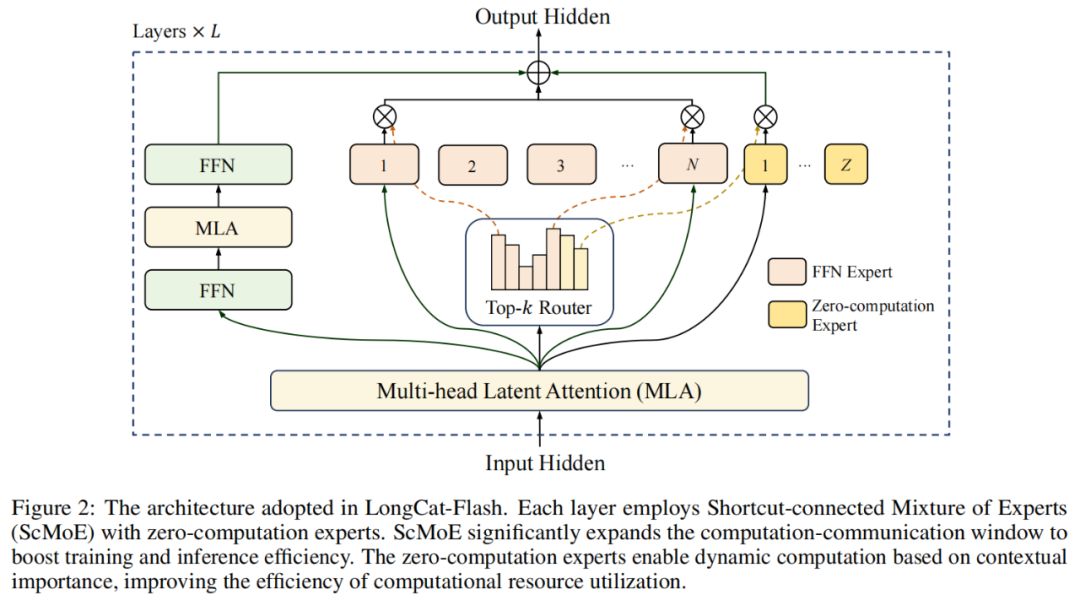
ゼロ計算エキスパート
ゼロ計算エキスパートの核心は、すべてのtokenが「平等」ではないという考え方です。
例えば、ある文の中で「の」「は」などの単語は予測が非常に容易で、ほとんど計算が不要ですが、「人名」などは正確に予測するために多くの計算が必要です。
従来の研究では、tokenが単純か複雑かに関わらず、固定数(K)のエキスパートをアクティブにしていました。これが大きな計算の無駄を生みます。単純なtokenには多くのエキスパートを呼び出す必要はなく、複雑なtokenには十分な計算が割り当てられない場合もあります。
この発想から、LongCat-Flashは動的計算リソース割り当てメカニズムを提案。ゼロ計算エキスパートを通じて、各tokenに異なる数のFFN(Feed-Forward Network)エキスパートを動的にアクティブにし、文脈の重要度に応じて計算量を合理的に分配します。
具体的には、LongCat-Flashのエキスパートプールには、従来のN個の標準FFNエキスパートに加え、Z個のゼロ計算エキスパートを追加。ゼロ計算エキスパートは入力をそのまま出力するだけなので、追加の計算コストは発生しません。
LongCat-FlashのMoEモジュールは次のように形式化できます:
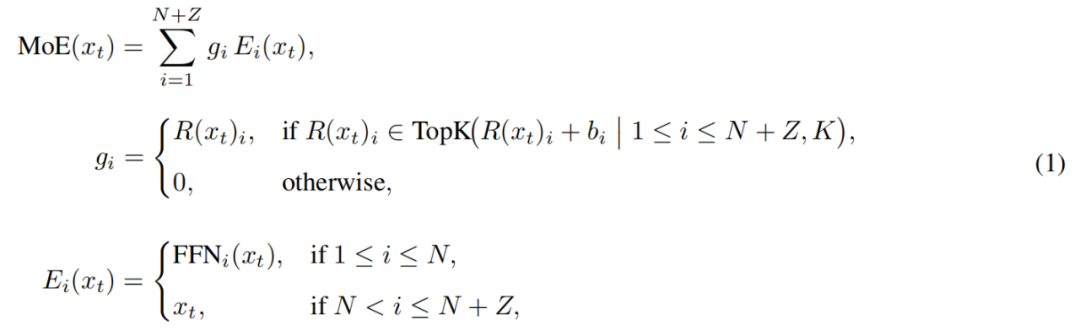
ここで、x_tは入力シーケンス中のt番目のtoken、Rはsoftmaxルーター、b_iはi番目のエキスパートのバイアス、Kは各tokenが選択するエキスパート数を表します。ルーターは各tokenをK個のエキスパートに割り当て、アクティブなFFNエキスパート数はそのtokenの文脈重要度に応じて変化します。この適応的な割り当てメカニズムにより、モデルは文脈上重要なtokenにより多くの計算リソースを動的に割り当て、同じ計算量でもより優れた性能を実現します(図3a参照)。
また、モデルは入力処理時にtokenの重要度に応じて、より多くの計算リソースを使うかどうかを判断する必要があります。ゼロ計算エキスパートの選択頻度を制御しないと、モデルは計算ありエキスパートを選びがちになり、ゼロ計算エキスパートの役割を無視してしまい、計算リソースの効率が低下します。
この問題を解決するため、Meituanはaux-loss-free戦略のエキスパートバイアスメカニズムを改良。エキスパート固有のバイアス項を導入し、直近のエキスパート使用状況に応じてルーティングスコアを動的に調整しつつ、言語モデルのトレーニング目標とはデカップリングしています。
更新ルールには制御理論のPIDコントローラーを用いてエキスパートバイアスをリアルタイム調整。このおかげで、各token処理時に18.6 billionsから31.3 billions(平均約27 billions)のパラメータのみをアクティブにし、リソースの最適化を実現しています。
ショートカット接続MoE
LongCat-Flashのもう一つの特徴はショートカット接続MoE(ScMoE)です。
一般に、大規模MoEモデルの効率は通信コストに大きく左右されます。従来の実行パラダイムでは、エキスパート並列化がシーケンシャルなワークフローを生み、まず全体通信でtokenを割り当ててから計算を開始する必要がありました。
この「通信→計算」の順序は追加の待ち時間を生み、特に大規模分散トレーニングでは通信遅延が顕著なボトルネックとなります。
過去には共有エキスパートアーキテクチャで通信と単一エキスパート計算の重複を試みましたが、単一エキスパート計算ウィンドウが小さすぎて効率が上がりませんでした。
MeituanはScMoEアーキテクチャを導入し、この制限を克服。ScMoEは層間にショートカット接続を設け、前層の密集FFN計算と現MoE層の分配/集約通信を並列実行できるようにし、共有エキスパートアーキテクチャよりも大きな通信-計算重複ウィンドウを形成します。
このアーキテクチャ設計は多くの実験で検証されています。
まず、ScMoE設計はモデル品質を低下させません。図4のように、ScMoEアーキテクチャと非ScMoEベースラインのトレーニング損失曲線はほぼ一致し、この実行順序の再編成がモデル性能を損なわないことを示しています。この結論は様々な設定で一貫して確認されています。
さらに重要なのは、これらの結果が示すのは、ScMoEの安定性と性能優位性は注意機構の選択とは直交している(どの注意機構でも安定と利得が得られる)ということです。
次に、ScMoEアーキテクチャはトレーニングと推論の両方で大幅なシステム効率向上をもたらします。具体的には:
大規模トレーニング面:拡張された重複ウィンドウにより、前段ブロックの計算とMoE層の分配・集約通信を完全に並列化。これはtoken軸で操作を細粒度ブロックに分割することで実現。
高効率推論面:ScMoEは単一バッチ重複パイプラインをサポートし、DeepSeek-V3などの先進モデルと比べて理論的な毎秒出力token時間(TPOT)を約50%削減。さらに、異なる通信モードの並行実行が可能で、密集FFNのノード内テンソル並列通信(NVLink経由)とノード間エキスパート並列通信(RDMA経由)が完全に重複し、ネットワーク利用率を最大化。
要するに、ScMoEはモデル品質を損なうことなく大幅な性能向上を実現します。
モデル拡張戦略と多段階トレーニング
Meituanはさらに効率的なモデル拡張戦略を提案し、モデル規模拡大時の性能向上を大幅に改善しました。
まずはハイパーパラメータの移行。超大規模モデルのトレーニングでは、様々なハイパーパラメータを直接試すのは高コストかつ不安定です。そこでMeituanはまず小規模モデルで実験し、最適なハイパーパラメータを見つけてから大規模モデルに移行。コストを抑えつつ効果を保証します。移行ルールは表1参照。
次にモデル成長(Model Growth)初期化。Meituanは数百億tokenで事前学習した半規模モデルからスタートし、トレーニング後にチェックポイントを保存。その後、モデルを完全規模に拡張し、トレーニングを継続します。
この方法により、モデルは典型的な損失曲線を示します。損失が一時的に上昇した後、急速に収束し、最終的にはランダム初期化ベースラインを大きく上回ります。図5bは6Bアクティブパラメータ実験の代表的な結果で、モデル成長初期化の優位性を示しています。
三つ目は多層的な安定性スイート。Meituanはルーター安定性、アクティベーション安定性、オプティマイザ安定性の三方面からLongCat-Flashのトレーニング安定性を強化しました。
四つ目は決定論的計算。この方法により、実験結果の完全な再現性が保証され、トレーニング中のサイレントデータ破損(Silent Data Corruption, SDC)も検出できます。
これらの施策により、LongCat-Flashのトレーニングプロセスは常に高い安定性を保ち、回復不能な損失急増(loss spike)は発生しません。
トレーニングの安定性を保った上で、Meituanはさらにトレーニングパイプラインを精緻に設計し、LongCat-Flashに高度なエージェント行動を持たせました。このプロセスは大規模事前学習、推論・コード能力向上の中期トレーニング、対話・ツール利用に特化した後期トレーニングを含みます。
初期段階では、エージェント後期トレーニングに適した基礎モデルを構築するため、Meituanは2段階の事前学習データ融合戦略を設計し、推論集約型分野のデータを集中させました。
中期トレーニングでは、推論能力とコード能力をさらに強化。同時に文脈長を128kまで拡張し、エージェント後期トレーニングのニーズに対応。
最後に、多段階の後期トレーニングを実施。エージェント分野の高品質・高難度トレーニングデータが希少なため、Meituanは多エージェント合成フレームワークを設計。このフレームワークは情報処理、ツールセットの複雑性、ユーザーインタラクションの3軸でタスク難易度を定義し、専用コントローラーで反復推論と環境インタラクションが必要な複雑タスクを生成します。
この設計により、ツール呼び出しや環境インタラクションが必要な複雑タスクでも優れたパフォーマンスを発揮します。
高速かつ低コストで動作
LongCat-Flashはどうやって実現したのか?
前述の通り、LongCat-FlashはH800 GPU上で毎秒100token超の推論速度を実現し、コストは100万出力tokenあたり0.7ドル。まさに高速かつ低コストです。
その理由は?まず、モデルアーキテクチャと協調設計された並列推論アーキテクチャを持ち、さらに量子化やカスタムカーネルなどの最適化手法も導入しています。
専用最適化:モデルが「自分でスムーズに動く」ように
高効率な推論システムを構築するには、計算と通信の協調、KVキャッシュの読み書き・保存という2つの課題を解決する必要があります。
1つ目の課題に対し、既存手法は通常3つの粒度で並列性を活用します:オペレータレベル、エキスパートレベル、レイヤーレベルの重複。LongCat-FlashのScMoEアーキテクチャは第4の次元——モジュールレベルの重複を導入。これにより、チームはSBO(Single Batch Overlap)スケジューリング戦略を設計し、レイテンシとスループットを最適化しました。
SBOは4段階のパイプライン実行方式で、モジュールレベルの重複を最大限活用しLongCat-Flashの潜在力を引き出します(図9参照)。SBOとTBOの違いは、通信コストを単一バッチ内で隠蔽する点です。第1段階でMLA計算を実行し、後続段階に入力を提供。第2段階ではDense FFNとAttn 0(QKV投影)をall-to-all dispatch通信と重複。第3段階でMoE GEMMを独立実行し、広範なEP展開戦略の恩恵を受けます。第4段階ではAttn 1(コアアテンションと出力投影)およびDense FFNをall-to-all combineと重複。この設計により通信コストを効果的に緩和し、LongCat-Flashの高効率推論を保証します。
2つ目の課題——KVキャッシュの読み書き・保存——については、LongCat-Flashは注意機構とMTP構造のアーキテクチャ革新で、I/Oコストを削減しています。
まずは推測デコード加速。LongCat-FlashはMTPをドラフトモデルとして用い、システム分析による推測デコード加速式で3つの要素(期待受理長、ドラフトとターゲットモデルのコスト比、ターゲット検証とデコードのコスト比)を最適化。単一MTPヘッドを統合し、事前学習後期に導入することで約90%の受理率を実現。ドラフト品質と速度のバランスを取るため、軽量MTPアーキテクチャでパラメータを削減し、C2T手法で分類モデルにより受理されにくいtokenをフィルタリング。
次にKVキャッシュ最適化。MLAの64ヘッドアテンション機構により、性能と効率のバランスを保ちつつ計算負荷を大幅に削減し、優れたKVキャッシュ圧縮を実現。保存・帯域負荷を低減します。これはLongCat-Flashのパイプライン調整に不可欠で、モデルは通信と重複できないアテンション計算を常に持つためです。
システムレベル最適化:ハードウェアの「チームワーク」
スケジューリングコストを最小化するため、LongCat-Flash研究チームはLLM推論システムでカーネル起動コストによるlaunch-bound問題を解決。特に推測デコード導入後、検証カーネルとドラフト前方伝播の独立スケジューリングで顕著なコストが発生します。TVD融合戦略により、ターゲット前方、検証、ドラフト前方を単一CUDAグラフに統合。さらにGPU利用率向上のため、重複スケジューラを実装し、マルチステップ重複スケジューラで1回のスケジューリングで複数前方ステップのカーネルを起動し、CPUスケジューリングと同期コストを効果的に隠蔽。
カスタムカーネル最適化はLLM推論の自己回帰特有の効率課題に対応。プリフィル段階は計算集約型、デコード段階はトラフィックパターンにより小規模かつ不規則なバッチサイズでメモリ制約が生じやすい。MoE GEMMではSwapAB技術で重みを左行列、アクティベーションを右行列とし、n次元8要素粒度の柔軟性でテンソルコア利用率を最大化。通信カーネルはNVLink Sharpのハードウェア加速ブロードキャストとin-switchリダクションを活用し、データ移動とSM占有率を最小化。4スレッドブロックのみで4KB〜96MBのメッセージサイズ範囲でNCCLやMSCCL++を継続的に上回ります。
量子化面では、LongCat-FlashはDeepSeek-V3と同じ細粒度ブロックレベル量子化方式を採用。最適な性能-精度バランスを実現するため、2つの方式に基づく階層的混合精度量子化を実装。1つ目は特定の線形層(特にDownproj)の入力アクティベーションが10^6に達する極端な振幅を持つことを識別。2つ目は層ごとにブロックレベルFP8量子化誤差を計算し、特定エキスパート層で顕著な量子化誤差があることを発見。2方式の交差を取ることで精度を大幅に向上。
実測データ:どれだけ速く、どれだけ安い?
実測性能では、LongCat-Flashは様々な設定で優れたパフォーマンスを示しています。DeepSeek-V3と比較して、同等の文脈長でより高い生成スループットとより速い生成速度を実現。
Agentアプリケーションでは、推論内容(ユーザー可視、約20tokens/sの人間読解速度に合わせる必要あり)とアクションコマンド(ユーザー不可視だがツール呼び出し起動時間に直結し最高速度が必要)の異なるニーズを考慮し、LongCat-Flashの約100tokens/s生成速度は単一ツール呼び出し遅延を1秒以内に抑え、Agentアプリのインタラクティブ性を大幅に向上。H800 GPUが1時間2ドルの場合、100万出力tokenあたりの価格は0.7ドルとなります。
理論性能分析では、LongCat-Flashのレイテンシは主にMLA、all-to-all dispatch/combine、MoEの3要素で決まります。EP=128、1カードあたりバッチ=96、MTP受理率≈80%等の仮定で、LongCat-Flashの理論限界TPOTは16ms、DeepSeek-V3の30ms、Qwen3-235B-A22Bの26.2msより大きな優位性。H800 GPUが1時間2ドルの場合、LongCat-Flashの出力コストは100万tokenあたり0.09ドルで、DeepSeek-V3の0.17ドルより大幅に低い。ただし、これらは理論限界値です。
LongCat-Flashの無料体験ページでもテストしてみました。
まず、この大規模モデルに秋についての1000字程度の文章を書かせてみました。
リクエストを出して録画を始めた瞬間、LongCat-Flashはすでに答えを書き終えており、録画をすぐに止める暇もありませんでした。
よく観察すると、LongCat-Flashの最初のtoken出力速度が非常に速いことがわかります。他の対話モデルでは、しばしば「ぐるぐる」待たされ、ユーザーの忍耐力が試されます。まるで急いでWeChatを見たいのに、スマホの信号が「受信中」と表示されているようなものです。LongCat-Flashはこの体験を変え、最初のtokenの遅延をほとんど感じさせません。
その後のtoken生成速度も非常に速く、人間の読解速度をはるかに上回ります。
次に、「ネット検索」をオンにして、LongCat-Flashのこの機能がどれだけ速いかを試しました。望京周辺の美味しいレストランを推薦してもらいました。
テストの結果、LongCat-Flashは長く考えてからゆっくり答えるのではなく、ほぼ即座に回答を返してくれます。ネット検索も「速い」と感じます。しかも、迅速な出力と同時に出典も添付してくれるので、情報の信頼性と追跡性も確保されています。
モデルをダウンロードできる環境の方は、ぜひローカルでLongCat-Flashの速度を体験してみてください。
大規模モデルが実用時代に突入
ここ数年、新しい大規模モデルが登場するたびに、みんなが気にしていたのは「ベンチマークデータは?」「いくつのランキングを更新した?」「SOTAか?」でした。今は状況が変わり、能力がほぼ同等なら「このモデルはコストが高い?」「速度はどう?」が重視されるようになりました。特にオープンソースモデルを使う企業や開発者では顕著です。多くのユーザーは、クローズドAPIへの依存とコストを下げるためにオープンソースモデルを使うので、計算リソース、推論速度、圧縮・量子化効果により敏感です。
Meituanがオープンソース化したLongCat-Flashは、まさにこのトレンドに応じた代表作です。彼らは「大規模モデルを本当に使えるように、速く動かす」ことに重点を置いており、これは技術普及の鍵となります。
この実用路線の選択は、私たちがMeituanに対して持っていた印象とも一致します。過去、彼らの技術投資の大部分は実際のビジネス課題の解決に使われてきました。例えば2022年にICRAで最優秀ナビゲーション論文を受賞したEDPLVOは、ドローン配送中の様々な予期せぬ事態(ビル密集で信号が途切れるなど)を解決するためのものでした。最近策定に参加したグローバルドローン障害回避ISO標準も、ドローンが飛行中に凧糸や窓拭き用ロープを避けるなどの事例から得た技術知見の蓄積です。そして今回オープンソース化されたLongCat-Flashは、彼らのAIプログラミングツール「NoCode」の裏側のモデルであり、このツールは社内外で無料開放され、みんながvibe codingを活用しコスト削減と効率向上を実現できるようにしています。
この「性能競争から実用志向への転換」は、AI業界発展の自然な流れを反映しています。モデル能力が拮抗してくると、エンジニアリング効率とデプロイコストが差別化の鍵となります。LongCat-Flashのオープンソース化はこのトレンドの一例に過ぎませんが、「モデル品質を維持しつつ、アーキテクチャ革新とシステム最適化で利用ハードルを下げる」技術ルートをコミュニティに提供したのは確かです。これは、限られた予算でも先進AI能力を活用したい開発者や企業にとって、間違いなく価値あるものです。
免責事項:本記事の内容はあくまでも筆者の意見を反映したものであり、いかなる立場においても当プラットフォームを代表するものではありません。また、本記事は投資判断の参考となることを目的としたものではありません。
こちらもいかがですか?
海外KOLの混乱:ZachXBTが100万ドルの有料プロモーションの罠を暴露

Hash Global初のコンプライアンス対応BNB配当ファンドがYZi Labsの戦略的支援を獲得、初期目標規模は100ミリオンドル
このファンドは、機関レベルのカストディ、高いコストパフォーマンス、透明性のある運営を組み合わせることで、プライベートウェルスマネジメントプラットフォームやハイネットワース層に対し、世界時価総額第4位の暗号資産BNBへの便利かつ安全なアクセス手段を提供します。

分散型AIプロジェクトGAEAが1,000万ドルの戦略的資金調達を完了、人間とAIの新しい関係を構築
GAEAは、人間の感情データを統合した初の分散型AIトレーニングネットワークであり、プライバシーとセキュリティを前提に、リアルな人間性データをオープンソースAIプロジェクトがより簡単にアクセスし理解できるようにし、AIの進化を促進するネットワークプラットフォームを構築します。

BitgetとMorphパブリックチェーンの戦略的提携およびBGBポジショニングアップグレードに関するお知らせ