

Eine großflächige Serviceunterbrechung am 20. Oktober hat mehrere große Plattformen nach einem größeren Ausfall in der Infrastruktur von Amazon Web Services (AWS) vorübergehend vom Netz genommen.
Beliebte Apps wie Snapchat, Fortnite und Alexa waren stundenlang nicht zugänglich, was zeigt, wie sehr ein Großteil des Internets auf einige wenige große Cloud-Anbieter angewiesen ist.
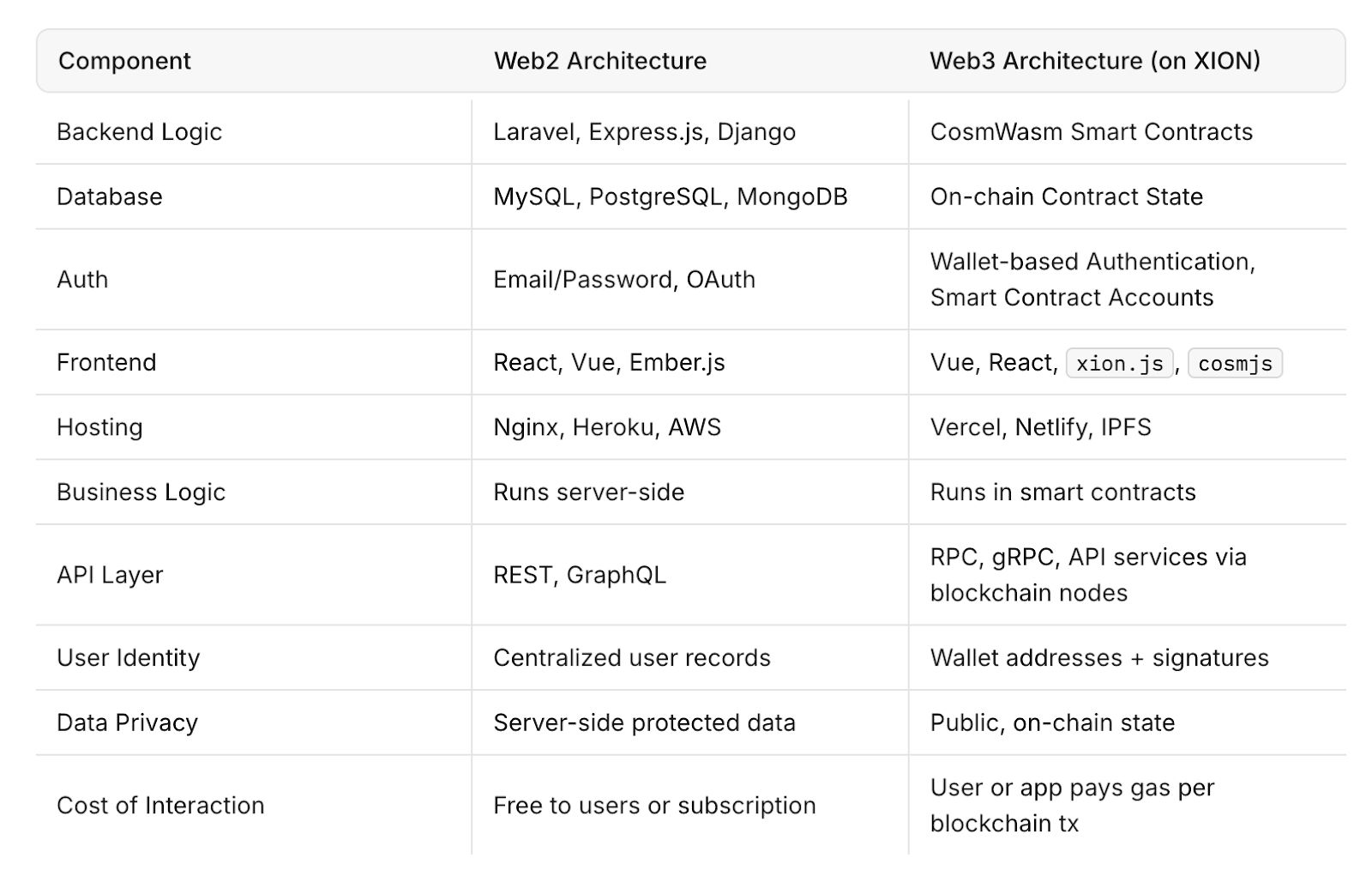
AWS-Ausfall deckte Web2-Schwachstellen auf und wie Web3-Designs die Ausfallsicherheit erhöhen
Die Veranstaltung machte deutlich, wie sehr das globale Internet von einer kleinen Anzahl zentralisierter Cloud-Anbieter abhängig ist. Es wurden auch Diskussionen über alternative Modelle neu belebt, insbesondere über dezentrale Systeme, die im Rahmen von Web3 gefördert werden und darauf abzielen, die Abhängigkeit von Single Points of Failure zu verringern.
Berichte über Verbindungsprobleme begannen gegen 3:11 Uhr ET, als Benutzer in den Vereinigten Staaten und Teilen Europas bemerkten, dass mehrere Apps und Websites nicht mehr funktionierten.
Amazon bestätigte bald, dass seine Region USA-East-1, einer seiner kritischsten Cloud-Hubs, „erhöhte Fehlerraten“ verzeichnete, die Dienste wie API Gateway, Lambda und CloudFront betrafen.
Innerhalb einer Stunde begannen Plattformen, die auf AWS-Hosting angewiesen waren, von Unterhaltungs- bis hin zu Unternehmensdienstleistungen, dunkel zu werden. Der AWS-Ausfall unterbrach den Kernbetrieb in mehreren Branchen, darunter E-Commerce, Gaming, Kommunikation und Finanzdienstleistungen.
Mehrere Stunden lang war es nicht möglich, auf Smart-Home-Funktionen zuzugreifen, sich bei sozialen Plattformen anzumelden oder Online-Transaktionen durchzuführen. Unternehmen, die in AWS-basierten Umgebungen arbeiten, sahen sich auch mit Ausfallzeiten in ihren internen Systemen konfrontiert, die den täglichen Betrieb und den Kundenservice beeinträchtigten.
Ursache des AWS-Ausfalls: Was Amazon bestätigt hat
Gegen Mittag identifizierten die Amazon-Ingenieure eine Fehlkonfiguration in einem Netzwerk-Update als Ursache. Das Problem störte die Art und Weise, wie interne Systeme Routing- und DNS-Vorgänge verwalteten, und verhinderte, dass Anfragen ihr Ziel erreichten. AWS-Teams haben das fehlerhafte Update rückgängig gemacht und den vollständigen Service bis zum späten Nachmittag schrittweise wiederhergestellt.
Amazon betonte, dass keine Kundendaten verloren gegangen oder kompromittiert wurden und dass das Problem auf eine einzige Region beschränkt war. Dennoch hat die Ausfallzeit deutlich gemacht, wie sich selbst ein lokales Problem durch das globale Web-Ökosystem ziehen kann, wenn so viele digitale Dienste von einer einzigen Infrastrukturschicht abhängen.
Welche Websites und Apps ausgefallen sind und warum sich die Auswirkungen ausgebreitet haben
Zu den sichtbarsten Störungen gehörten Amazons eigene Konsumgüter, darunter Alexa und Ring. Benutzer berichteten, dass intelligente Lautsprecher Sprachbefehle nicht verarbeiten konnten, während verbundene Kameras und Türklingeln nicht mehr auf die Steuerung mobiler Apps reagierten.
Im Unterhaltungs- und Gaming-Bereich kam es bei Titeln wie Fortnite, Roblox und PUBG zu Anmeldefehlern und Matchmaking-Fehlern. Viele dieser Spiele verlassen sich auf AWS für die Echtzeit-Multiplayer-Synchronisierung und die Cloud-basierte Bereitstellung von Inhalten.
Auch Social- und Kommunikationsplattformen waren betroffen. Snapchat-Benutzer hatten während des Höhepunkts des Ausfalls Schwierigkeiten, Nachrichten zu senden und Feeds zu laden. Darüber hinaus meldeten Slack, Zoom und mehrere Business-Tools, die auf der AWS-Infrastruktur basieren, zeitweilige Verbindungsprobleme, die sich auf den Remote-Arbeitsbetrieb auswirkten.
Einige Finanzanwendungen und Zahlungsabwickler, die die Rechen- und Speicherdienste von AWS nutzen, gingen kurzzeitig offline, was zu fehlgeschlagenen Transaktionen und Verzögerungen bei digitalen Zahlungen führte. Bei Einzelhandels- und E-Commerce-Websites, die auf AWS basieren, kam es ebenfalls zu vorübergehenden Ausfallzeiten oder langsameren Reaktionszeiten.
Warum die Zentralisierung den Explosionsradius auf der Bahn vergrößerte
Die Reichweite des Vorfalls zeigte, wie tief AWS in die täglichen Funktionen des Internets eingebettet ist. Ein einziger regionaler Ausfall erstreckte sich über die unmittelbare Geografie hinaus und unterbrach Verbraucher-, Unterhaltungs- und Unternehmenssysteme über mehrere Zeitzonen hinweg.
Dieser Fehler verdeutlichte auch, wie Service-Abhängigkeiten wie APIs und Integrationen von Drittanbietern die Auswirkungen eines Ausfalls weit über seine technische Ursache hinaus verteilen können.
Laut dem Bericht von Amazon nach dem Vorfall war die Störung auf eine fehlerhafte Konfigurationsänderung zurückzuführen, die während eines routinemäßigen Wartungsupdates eingeführt wurde. Die Änderung veränderte unbeabsichtigt die Art und Weise, wie interne DNS-Resolver den Datenverkehr leiteten, was dazu führte, dass Systeme die Verarbeitung von Anfragen stoppten.
Nach der Erkennung leiteten Amazon-Techniker ein Rollback des Updates ein und leiteten den Datenverkehr über Backup-Routen um. Die Wiederherstellung begann Region für Region, wobei sich der AWS-Ausfallstatus bis zum späten Nachmittag allmählich erholte.
Seitdem hat das Unternehmen zusätzliche Sicherheitsvorkehrungen getroffen, um ähnliche Probleme zu verhindern, darunter strengere Kontrollen des Änderungsmanagements und neue automatisierte Rollback-Verfahren für Netzwerk-Updates.
Zentralisierung vs. Dezentralisierung: Eine umfassendere Lektion
Dieser Vorfall hat die langjährige Debatte über Web2- und Web3-Modelle neu eröffnet. Im aktuellen Web2-Framework betreiben eine Handvoll Unternehmen, darunter Amazon, Google und Microsoft, den Großteil des weltweiten Webverkehrs über zentralisierte Server.
Diese Struktur bietet Komfort, Kosteneffizienz und Skalierbarkeit, konzentriert aber auch Kontrolle und Verwundbarkeit. Wenn es bei einem dieser Anbieter zu einer Störung kommt, sind die Auswirkungen sofort und weitreichend.
Branchenanalysten warnen seit langem davor, dass diese Konzentration von Hosting- und Datenmanagement-Power einen Single Point of Failure für das Internet schafft. Cloud Computing bietet zwar Skalierbarkeit und Kosteneffizienz, zentralisiert aber auch Risiken. Wenn die Systeme eines Schlüsselanbieters ausfallen, haben abhängige Dienste wenig Spielraum, um sich unabhängig zu erholen.
Der AWS-Ausfall hat auch eine weitere Herausforderung aufgedeckt, nämlich die miteinander verbundenen Abhängigkeiten. Viele Dienste arbeiten in mehrschichtigen Architekturen, bei denen die API oder Datenbank eines Anbieters mehrere nachgelagerte Plattformen unterstützt. Diese Struktur verstärkt die Auswirkungen technischer Störungen.
Experten gehen davon aus, dass Redundanz und der Einsatz in mehreren Regionen zwar das Risiko verringern können, das grundlegende Problem jedoch in der Struktur des Webs liegt. Zentralisierte Cloud-Modelle konsolidieren Kontrolle und Kapazität in wenigen Netzwerken, wodurch Ausfälle sowohl schwerwiegender als auch schwieriger zu isolieren sind.
Warum Experten Web3 als Alternative sehen
Web3 zielt darauf ab, dies zu ändern, indem es Rechenleistung und Datenspeicherung auf dezentrale Netzwerke unabhängiger Knoten verteilt. Im Gegensatz zu zentralisierten Cloud-Systemen sind dezentrale Architekturen nicht auf die Verfügbarkeit eines Anbieters angewiesen. Wenn ein Knoten oder Cluster ausfällt, können andere ohne Unterbrechung weiterbetrieben werden.
Für Entwickler und Unternehmen könnte dieser Ansatz eine größere Ausfallsicherheit, Transparenz und Sicherheit bedeuten, obwohl die Skalierung der dezentralen Infrastruktur an die Geschwindigkeit und Kapazität von Web2 eine Herausforderung bleibt.
Projekte wie Filecoin, Arweave und Akash Network sind Beispiele für dezentrale Infrastrukturlösungen, die darauf abzielen, Speicher- und Rechenleistung über offene Netzwerke bereitzustellen. Diese Systeme verwenden Anreizmechanismen, um die Betriebszeit und Datenverfügbarkeit ohne zentrale Aufsicht aufrechtzuerhalten.
 Quelle: XION
Quelle: XION
Die Web3-Infrastruktur befindet sich jedoch noch in einem frühen Stadium der Einführung. Es steht vor Herausforderungen in Bezug auf Skalierbarkeit, Geschwindigkeit und Benutzererfahrung im Vergleich zu etablierten Web2-Systemen. Trotzdem hat der AWS-Vorfall gezeigt, wie wertvoll es ist, alternative Modelle zu haben, die die Widerstandsfähigkeit des Internets verbessern können.
Gewonnene Erkenntnisse und der Weg in die Zukunft
Der Ausfall deutete darauf hin, dass die Widerstandsfähigkeit der digitalen Wirtschaft Redundanz und Diversifizierung erfordert. Unternehmen, die ihre Workloads auf mehrere Cloud-Regionen oder -Anbieter verteilten, erlebten weniger Ausfallzeiten und schnellere Wiederherstellungszeiten. Andere, die vollständig von AWS abhängig waren, mussten warten, bis Amazon seine Systeme wiederhergestellt hatte.
Es zeigte sich auch, wie Abhängigkeitsketten Störungen verstärken. Viele Anwendungen hosteten ihre primären Services nicht auf AWS, gingen aber dennoch offline, weil sie von AWS gehostete APIs, Analysen oder Authentifizierungstools verwendeten. Ein Single Point of Failure in der Kette löste Ausfälle auf nicht verwandten Plattformen aus.
Das Ereignis könnte mehrere Unternehmen dazu veranlassen, ihre Infrastrukturstrategien zu überdenken und hybride Modelle zu erforschen, die traditionelle Cloud-Systeme mit dezentraler Speicherung und Datenverarbeitung kombinieren.
Entwickler und Unternehmen gleichermaßen betrachten die Dezentralisierung nicht nur als Trend, sondern auch als praktischen Schutz vor großen Ausfallzeiten.
Amazon hat erklärt, dass neue Überwachungsmechanismen und interne Rollback-Kontrollen jetzt in allen Regionen aktiv sind. Experten weisen jedoch darauf hin, dass technische Korrekturen allein die inhärenten Risiken der Zentralisierung nicht vollständig ausräumen können.
Mit der zunehmenden globalen digitalen Abhängigkeit kann die Widerstandsfähigkeit davon abhängen, wie effektiv Cloud Computing und dezentrale Technologien koexistieren können.
FAQs
Was hat den AWS-Ausfall verursacht?
Amazon sagte, dass ein Konfigurationsfehler während eines routinemäßigen Updates in der Region US-East-1 das Netzwerk-Routing und die DNS-Funktionen unterbrochen habe. Das Problem wurde innerhalb weniger Stunden eingedämmt, und es wurden keine Daten- oder Sicherheitsverletzungen gemeldet.
Welche Websites und Apps waren betroffen?
Plattformen wie Alexa, Ring, Snapchat, Fortnite und Roblox gingen offline. Auch Geschäfts- und Zahlungstools, die die AWS-Infrastruktur nutzen, waren mit vorübergehenden Unterbrechungen konfrontiert.
Warum macht die Zentralisierung das Internet verwundbar?
Zentralisierte Systeme sind auf einige wenige große Anbieter angewiesen, sodass ein Ausfall Millionen von Benutzern betreffen kann. Dezentrale Netzwerke verringern dieses Risiko, indem sie den Betrieb auf unabhängige Knoten verteilen.
Fazit
Der Vorfall im Oktober 2025 hat die Stärken und Schwächen einer modernen Cloud-Infrastruktur aufgezeigt. AWS gelang es, den Betrieb schnell wiederherzustellen, aber die globalen Auswirkungen zeigten, dass die Zuverlässigkeit Grenzen hat, wenn die Kontrolle bei einigen wenigen Anbietern liegt.
Für Unternehmen und Entwickler ist die Lektion, dass Diversifizierung und Dezentralisierung nicht mehr optional sind. Hybride Infrastrukturen, die zentralisierte Effizienz mit dezentraler Resilienz verbinden, könnten die nächste Ära der Internetzuverlässigkeit definieren.
Disclaimer: The information presented in this article is for informational and educational purposes only. The article does not constitute financial advice or advice of any kind. Coin Edition is not responsible for any losses incurred as a result of the utilization of content, products, or services mentioned. Readers are advised to exercise caution before taking any action related to the company.



